



SQL Server 2008에 sys.dm_exec_procedure_stats DMV가 추가되었습니다.
2008이전 버젼에서는 SP별로 실행정보를 보기 위해서는 statment단위로 저장된 데이터를
GROUP BY해서 확인했지만, SQL Server 2008부터는 해당 DMV가 추가됨에 따라
쉽게 바로 확인이 가능합니다.
SELECT * FROM (
SELECT TOP 10
db_name(qt.dbid) AS 'db_name'
,OBJECT_NAME(qt.objectid,qt.dbid) as sp_name
,qp.query_plan
,execution_count as execution_count
, ISNULL(qs.execution_count/DATEDIFF(Second, qs.cached_time, GetDate()), 0) AS 'Calls/Second'
, DATEDIFF(Minute, qs.cached_time, GetDate()) AS 'Age in Cache(min)'
,qs.cached_time
,qs.last_execution_time
, ISNULL(qs.total_elapsed_time/qs.execution_count, 0) /1000.0 AS 'avg_Elapsed_Time(ms)'
, qs.total_elapsed_time/1000.0/1000.0 AS 'total_Elapsed_Time(sec)'
, max_elapsed_time /1000.0 AS 'max_Elapsed_Time(ms)'
, ISNULL(qs.total_worker_time/qs.execution_count, 0)/1000.0 AS 'avg_worker_time(ms)'
, total_worker_time/1000.0/1000.0 as 'total_worker_time(sec)'
, qs.max_worker_time/1000.0 as 'max_worker_time(msdb)'
, ISNULL(qs.total_logical_reads/qs.execution_count, 0) AS 'avg_logical_reads'
, total_logical_reads as total_logical_reads
, qs.max_logical_reads as max_logical_reads
, ISNULL(qs.total_physical_reads/qs.execution_count, 0) AS 'avg_physical_reads'
, total_physical_reads as total_physical_reads
, qs.max_physical_reads as max_physical_reads
, ISNULL(qs.total_logical_writes/qs.execution_count, 0) AS 'avg_physical_writes'
, qs.total_logical_writes as total_logical_writes
, qs.max_logical_writes as max_logical_writes
FROM sys.dm_exec_procedure_stats AS qs
CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) AS qt
CROSS APPLY sys.dm_exec_query_plan(qs.plan_handle) qp
where db_name(qt.dbid) is not null
)X
order by
[avg_worker_time(ms)]
DESC

송 혁, SQL Server MVP
sqler.com // sqlleader.com
hyoksong.tistory.com
SQL Server 2008에 재미있는 옵티마이저 기능이 추가 되었습니다.
하지만 버그로 인해서 SP1 또는 RTM CU4부터는 이 기능을 사용할 수 없었지만,
얼마 전에 나온 SP1 CU5에서 버그를 수정하여 이 기능을 다시 제공하고 있습니다.
Parameter Embedding Optimization이라고 불리며, OPTION(RECOMPILE)을 사용하는 쿼리의 경우 실행계획을 컴파일 할 때 실제 매개변수의 값을 가지고 컴파일 하는 기능입니다. 그렇다면 분명 기존보다 효율적인 플랜을 만들어줄 것 입니다. 뭐 당연하다고 생각할 수 도 있을 것 같습니다. 플랜 캐시를 재사용을 포기하며 recompile옵션도 추가했는데~ 플랜까지 이상하다면 좀 이상하겠죠!
이 기능이 도움을 줄 수 있는 경우는 쿼리가 변수에 따라서 플랜이 변경되어야 하는 경우 입니다.
입력되는 변수에 따라 WHERE 조건이 변경되는 경우 SQL Server 2008 이전 버전을 사용했을 때 적절한 플랜으로 처리 되기 위해서는 모든 경우에 따라 분기 문 또는 SP를 분리하여 사용하거나, 쿼리 문자열을 조합하는 형태의 동적 쿼리를 사용할 수 밖에 없었습니다. 동적 쿼리는 플랜 재사용도 거의 안되면서 플랜캐시에 상주할 수 있기에 플랜 캐시가 늘어나는 문제와 보안적인 문제를 가질 수 있습니다. 경우의 수만큼 분기 문을 사용한 쿼리는 유지 보수를 하기가 참~ 어려웠습니다.
그럼 이 기능으로 플랜이 어떻게 변경되는지 확인해 보겠습니다.
SQL Server 2008 SP1 + CU5와 SQL Server 2008 SP1 버전으로 비교해 보았습니다.
[테스트 1] 입력되는 변수 값에 따라 WHERE 조건이 변경되는 경우
SP1과 SP1 + CU5환경에서 실행하면 아래와 같은 실행계획을 확인 할 수 있습니다.
SP1의 경우는 TABLE SCAN으로 풀렸으며, SP1+CU5의 경우는 Index Seek + RID Lookup을 사용하였습니다.
아래 플랜에서 노란색으로 표시된 부분을 보면 SP1의 경우 조건 절에서 변수로 비교하며, CU5의 경우 상수로 비교하고 있습니다.
그래서 플랜이 서로 다른 모습을 보여주고 있으며, CU5가 파라미터의 값을 가지고 플랜을 생성하여 보다 효율적인 쿼리 플랜을 생성했습니다.
SQL Server 2008 SP1
|
Rows |
Executes |
StmtText |
|
1 |
1 |
SELECT * FROM tbl90 WHERE (col1 = @a AND @a IS NOT NULL) OR (col2 = @a2 AND @a2 IS NOT NULL) OR (col3 = @a3 AND @a3 IS NOT NULL) OR (col4 = @a4 AND @a4 IS NOT NULL) OR (col5 = @a5 AND @a5 IS NOT NULL) OR (col6 = @a6 AND @a6 IS NOT NULL) OPTION(RECOMPILE) |
|
1 |
1 |
|--Table Scan(OBJECT:([test].[dbo].[tbl90]), WHERE:([test].[dbo].[tbl90].[col1]=[@a] AND [@a] IS NOT NULL OR [test].[dbo].[tbl90].[col2]=[@a2] AND [@a2] IS NOT NULL OR [test].[dbo].[tbl90].[col3]=[@a3] AND [@a3] IS NOT NULL OR [test].[dbo].[tbl90].[col4]=[@a4] AND [@a4] IS NOT NULL OR [test].[dbo].[tbl90].[col5]=[@a5] AND [@a5] IS NOT NULL OR [test].[dbo].[tbl90].[col6]=[@a6] AND [@a6] IS NOT NULL)) |
SQL Server 2008 SP1 + CU5
|
Rows |
Executes |
StmtText |
|
1 |
1 |
SELECT * FROM tbl90 WHERE (col1 = @a AND @a IS NOT NULL) OR (col2 = @a2 AND @a2 IS NOT NULL) OR (col3 = @a3 AND @a3 IS NOT NULL) OR (col4 = @a4 AND @a4 IS NOT NULL) OR (col5 = @a5 AND @a5 IS NOT NULL) OR (col6 = @a6 AND @a6 IS NOT NULL) OPTION(RECOMPILE) |
|
1 |
1 |
|--Nested Loops(Inner Join, OUTER REFERENCES:([Bmk1000])) |
|
1 |
1 |
|--Index Seek(OBJECT:([tempdb].[dbo].[tbl90].[ix_tbl903]), SEEK:([tempdb].[dbo].[tbl90].[col3]=(1)) ORDERED FORWARD) |
|
1 |
1 |
|--RID Lookup(OBJECT:([tempdb].[dbo].[tbl90]), SEEK:([Bmk1000]=[Bmk1000]) LOOKUP ORDERED FORWARD) |
DROP TABLE tbl90
CREATE TABLE tbl90 (col1 INT NOT NULL, col2 INT ,col3 INT,col4 INT,col5 INT,col6 INT)
INSERT INTO tbl90
SELECT TOP 100000
ROW_NUMBER() OVER(ORDER BY(SELECT 1)),
ROW_NUMBER() OVER(ORDER BY(SELECT 1)),
ROW_NUMBER() OVER(ORDER BY(SELECT 1)),
ROW_NUMBER() OVER(ORDER BY(SELECT 1)),
ROW_NUMBER() OVER(ORDER BY(SELECT 1)),
ROW_NUMBER() OVER(ORDER BY(SELECT 1))
FROM sys.sysindexes a,sys.sysindexes a1,sys.sysindexes a2,sys.sysindexes a3
CREATE INDEX ix_tbl90 ON tbl90 (col1)
CREATE INDEX ix_tbl902 ON tbl90 (col2)
CREATE INDEX ix_tbl903 ON tbl90 (col3)
CREATE INDEX ix_tbl904 ON tbl90 (col4)
CREATE INDEX ix_tbl905 ON tbl90 (col5)
-- CREATE INDEX ix_tbl906 ON tbl90 (col6)
GO
CREATE PROC UP_90
@a INT = NULL
,@a2 INT = NULL
,@a3 INT = NULL
,@a4 INT = NULL
,@a5 INT = NULL
,@a6 INT = NULL
AS
SELECT * FROM tbl90
WHERE
(col1 = @a AND @a IS NOT NULL)
OR (col2 = @a2 AND @a2 IS NOT NULL)
OR (col3 = @a3 AND @a3 IS NOT NULL)
OR (col4 = @a4 AND @a4 IS NOT NULL)
OR (col5 = @a5 AND @a5 IS NOT NULL)
OR (col6 = @a6 AND @a6 IS NOT NULL)
OPTION(RECOMPILE)
GO
SET STATISTICS PROFILE ON
exec up_90 @a3 = 3
[테스트 2] 입력되는 변수 값에 따라 조회하는 테이블이 변경되는 경우
UNION ALL을 통해서 변수 값에 조회할 테이블을 선택할 수 있는 경우 입니다.
많이 사용되는 쿼리 중 하나인데요, SP1 + CU5버전에서 RECOMPILE옵션을
추가하면 입력된 변수 값에 따라 실질적으로 읽어야 할 테이블에 대해서만 조회를 하는 것을 볼 수 있습니다.
SQL Server 2008 SP1 + CU5
|
Rows |
Executes |
StmtText |
|
1 |
1 |
SELECT * FROM tbl90 WITH(NOLOCK) WHERE @a IS NOT NULL AND @a = col1 UNION ALL SELECT * FROM tbl91 WITH(NOLOCK) WHERE @a1 IS NOT NULL AND @a1 = col1 OPTION(RECOMPILE) |
|
0 |
0 |
|--Compute Scalar(DEFINE:([Union1008]=[tempdb].[dbo].[tbl90].[col1], [Union1009]=[tempdb].[dbo].[tbl90].[col2], [Union1010]=[tempdb].[dbo].[tbl90].[col3], [Union1011]=[tempdb].[dbo].[tbl90].[col4], [Union1012]=[tempdb].[dbo].[tbl90].[col5], [Union1013]=[tempdb].[dbo].[tbl90].[col6])) |
|
1 |
1 |
|--Nested Loops(Inner Join, OUTER REFERENCES:([Bmk1000])) |
|
1 |
1 |
|--Index Seek(OBJECT:([tempdb].[dbo].[tbl90].[ix_tbl90]), SEEK:([tempdb].[dbo].[tbl90].[col1]=(1)) ORDERED FORWARD) |
|
1 |
1 |
|--RID Lookup(OBJECT:([tempdb].[dbo].[tbl90]), SEEK:([Bmk1000]=[Bmk1000]) LOOKUP ORDERED FORWARD) |
SQL Server 2008 SP1
|
Rows |
Executes |
StmtText |
|
1 |
1 |
SELECT * FROM tbl90 WITH(NOLOCK) WHERE @a IS NOT NULL AND @a = col1 UNION ALL SELECT * FROM tbl91 WITH(NOLOCK) WHERE @a1 IS NOT NULL AND @a1 = col1 OPTION(RECOMPILE) |
|
1 |
1 |
|--Concatenation |
|
1 |
1 |
|--Nested Loops(Inner Join, OUTER REFERENCES:([Bmk1000])) |
|
1 |
1 |
| |--Filter(WHERE:(STARTUP EXPR([@a] IS NOT NULL))) |
|
1 |
1 |
| | |--Index Seek(OBJECT:([TEST2].[dbo].[tbl90].[ix_tbl90]), SEEK:([TEST2].[dbo].[tbl90].[col1]=[@a]) ORDERED FORWARD) |
|
1 |
1 |
| |--RID Lookup(OBJECT:([TEST2].[dbo].[tbl90]), SEEK:([Bmk1000]=[Bmk1000]) LOOKUP ORDERED FORWARD) |
|
0 |
1 |
|--Nested Loops(Inner Join, OUTER REFERENCES:([Bmk1004])) |
|
0 |
1 |
|--Filter(WHERE:(STARTUP EXPR([@a1] IS NOT NULL))) |
|
0 |
0 |
| |--Index Seek(OBJECT:([TEST2].[dbo].[tbl91].[ix_tbl91]), SEEK:([TEST2].[dbo].[tbl91].[col1]=[@a1]) ORDERED FORWARD) |
|
0 |
0 |
|--RID Lookup(OBJECT:([TEST2].[dbo].[tbl91]), SEEK:([Bmk1004]=[Bmk1004]) LOOKUP ORDERED FORWARD) |
DROP TABLE tbl91
CREATE TABLE tbl91 (col1 INT NOT NULL, col2 INT ,col3 INT,col4 INT,col5 INT,col6 INT)
INSERT INTO tbl91
SELECT TOP 100000
ROW_NUMBER() OVER(ORDER BY(SELECT 1)),
ROW_NUMBER() OVER(ORDER BY(SELECT 1)),
ROW_NUMBER() OVER(ORDER BY(SELECT 1)),
ROW_NUMBER() OVER(ORDER BY(SELECT 1)),
ROW_NUMBER() OVER(ORDER BY(SELECT 1)),
ROW_NUMBER() OVER(ORDER BY(SELECT 1))
FROM sys.sysindexes a,sys.sysindexes a1,sys.sysindexes a2,sys.sysindexes a3
CREATE INDEX ix_tbl91 ON tbl91 (col1)
CREATE INDEX ix_tbl912 ON tbl91 (col2)
CREATE INDEX ix_tbl913 ON tbl91 (col3)
CREATE INDEX ix_tbl914 ON tbl91 (col4)
CREATE INDEX ix_tbl915 ON tbl91 (col5)
CREATE INDEX ix_tbl916 ON tbl91 (col6)
GO
CREATE PROC UP_93
@a INT = NULL
,@a1 INT = NULL
AS
SELECT * FROM tbl90 WITH(NOLOCK) WHERE @a IS NOT NULL AND @a = col1
UNION ALL
SELECT * FROM tbl91 WITH(NOLOCK) WHERE @a1 IS NOT NULL AND @a1 = col1
OPTION(RECOMPILE)
GO
EXEC UP_93 @a = 1
추가적인 정보는 아래 링크를 참조하세요.
http://connect.microsoft.com/SQLServer/feedback/ViewFeedback.aspx?FeedbackID=244298
http://support.microsoft.com/kb/976603/
송 혁, SQL Server MVP
sqler.com // sqlleader.com
hyoksong.tistory.com
전체 백업 실패 후 차등 백업을 하게 되면, 기존 차등 백업 보다 파일 크기가 커지는 현상이 발생할 수 있습니다.
DCM페이지(Differential Changed Map)는 최근 전체 백업 이후에 변경된 페이지만을 마킹하게 되며
차등 백업은 DCM페이지에 마킹된 페이지만을 백업하게 됩니다.
그렇다면 전체 백업을 할 때 기존에 마킹 되어있던 DCM페이지를 초기화 해야 하는 작업이 필요 하며,
이러한 작업은 비문서화된 TRACE FLAG를 통해 확인할 수 있습니다.
DBCC TRACEON(3004, 3605,3213,3604, -1) 을 통해 아래와 같이 확인이 가능합니다.
이 TRACE FLAG의 정보를 통해 백업 동작 방식에 대해 조금 더 깊게 이해할 수 있습니다.
Backup: Clearing differential bitmaps
Backup: Bitmaps cleared
그렇다면, 전체 백업 단계 중 위 작업이 완료 되고, 전체 백업이 실패한다면?
과연 어떻게 될까 하는 생각에 테스트를 진행하였으며 결과는 차등 백업이 전체 백업 정도와 동일한 크기로 생성되게 됩니다.
뭐 이렇게 동작하는 이유는 단순하게 차등 백업은 DCM만을 활용하는 것이 아닌
트랜잭션 로그 또는 DB 부트 페이지 정보와 비교해서 판단하는 것이 아닐까 생각됩니다.
혹시 아시는 분 있으시면 공유 해주시면 감사하겠습니다.
Microsoft SQL Server 2008 (SP1) - 10.0.2531.0 (Intel X86)
Mar 29 2009 10:27:29
Copyright (c) 1988-2008 Microsoft Corporation
Developer Edition on Windows NT 6.1 <X86> (Build 7100: )
BACKUP DATABASE TEST to disk = 'c:\1.bak'
파일 1에서 데이터베이스 'TEST', 파일 'TEST'에 대해 15232개의 페이지를 처리했습니다 .
파일 1에서 데이터베이스 'TEST', 파일 'TEST_log'에 대해 1개의 페이지를 처리했습니다 .
SELECT TOP 1000
row_number() over(order by (select 1)) as col1
,cast('' as char(5000)) as col2
INTO tbl11
FROM sys.sysindexes A,sys.sysindexes A1,sys.sysindexes A2,sys.sysindexes A3
BACKUP DATABASE TEST to disk = 'c:\2.bak' with DIFFERENTIAL
파일 1에서 데이터베이스 'TEST', 파일 'TEST'에 대해 1128개의 페이지를 처리했습니다 .
파일 1에서 데이터베이스 'TEST', 파일 'TEST_log'에 대해 4개의 페이지를 처리했습니다 .
SELECT TOP 1000
row_number() over(order by (select 1)) as col1
,cast('' as char(5000)) as col2
INTO tbl12
FROM sys.sysindexes A,sys.sysindexes A1,sys.sysindexes A2,sys.sysindexes A3
BACKUP DATABASE TEST to disk = 'c:\3.bak' --fail
메시지 3204, 수준 16, 상태 1, 줄 2
백업 또는 복원 작업이 중단되었습니다.
메시지 3013, 수준 16, 상태 1, 줄 2
BACKUP DATABASE이(가) 비정상적으로 종료됩니다.
사용자가 쿼리를 취소했습니다.
BACKUP DATABASE TEST to disk = 'c:\4.bak' with DIFFERENTIAL
파일 1에서 데이터베이스 'TEST', 파일 'TEST'에 대해 17232개의 페이지를 처리했습니다 .
파일 1에서 데이터베이스 'TEST', 파일 'TEST_log'에 대해 1개의 페이지를 처리했습니다 .
송 혁, SQL Server MVP
sqler.pe.kr // sqlleader.com
hyoksong.tistory.com
SQL Server 2008 SSMS에 향상된 기능 중 하나는 개체 탐색기 정보 창입니다.
아래 그림과 같이 개체 탐색기에 관련 데이터베이스, 테이블 및 SP등의 오브젝트의
추가적인 속성을 선택 하여 볼 수 있으며, 또한 오브젝트 이름으로 검색도 할 수 있습니다.

송 혁, SQL Server MVP
sqler.pe.kr // sqlleader.com
hyoksong.tistory.com
하지만, SQL Server 2008부터 sp_configure locks 옵션을 사용한다고 하더라도 서버는 어떠한 추가적인 영향을 받지 않습니다.
그리고 이후 버젼부터는 이 기능이 제거된다고 합니다.
이러한 변경으로 인해서 SQL Server 2008 버젼부터는 잠금에 대한 메모리를 조절 할 수 없으며,
잠금 에스컬레이션에 메모리 임계치 값이 이전 버젼과 달라졌습니다.
SQL Server 2005 / locks 기본값인 경우 - 메모리의 24%일 때 잠금 에스컬레이션 임계값에 도달
SQL Server 2008 / locks 기본값인 경우 - 메모리의 40%일 때 잠금 에스컬레이션 임계값에 도달
자세한 내용은 아래를 참고하세요.
<BOL에서>
이 규칙은 잠금 구성 옵션의 값을 검사합니다. 이 옵션은 사용 가능한 잠금의 최대 개수를 결정합니다. 이 옵션은 SQL Server 데이터베이스 엔진이 잠금에 사용하는 메모리 양을 제한합니다. 기본 설정은 0을 사용하면 데이터베이스 엔진이 시스템 요구 사항의 변화를 기준으로 동적으로 잠금 구조를 할당하거나 할당 취소할 수 있습니다.
잠금이 0이 아니면, 일괄 처리 작업이 중지되고, 지정된 값이 초과될 경우 "잠금 부족" 오류 메시지가 생성됩니다.
SQL Server에서 이 옵션 기능을 사용할 수 없어도 기존 스크립트과의 호환성을 위해 sp_configure 저장 프로시저에 이 옵션이 사용할 수 있습니다(설정의 영향 없음). 이 옵션으로 설정하면 대신 잠금 공간이 자동으로 할당됩니다.
.gif) 중요: 중요: |
|---|
| Microsoft SQL Server의 이후 버전에서는 이 기능이 제거됩니다. 새 개발 작업에서는 이 기능을 사용하지 말고, 현재 이 기능을 사용하는 응용 프로그램은 가능한 한 빨리 수정하십시오 |
<SQL Server 2005 – 잠금 에스컬레이션>
데이터베이스 엔진 인스턴스의 에스컬레이션 임계값
잠금 수가 잠금 에스컬레이션에 대한 메모리 임계값보다 커지면 데이터베이스 엔진에서 잠금 에스컬레이션을 트리거합니다. 메모리 임계값은 다음과 같은 locks 구성 옵션의 설정에 따라 다릅니다.
l locks 옵션을 기본값인 0으로 설정하면 잠금 개체에서 사용하는 메모리가 AWE 메모리를 제외하고 데이터베이스 엔진에서 사용하는 메모리의 24%일 때 잠금 에스컬레이션 임계값에 도달합니다. 잠금을 나타내는 데 사용되는 데이터 구조의 길이는 약 100바이트입니다. 데이터베이스 엔진이 다양한 작업에 맞추어 동적으로 메모리를 획득하거나 해제하기 때문에 이 임계값은 동적입니다.
l locks 옵션을 0 이외의 값으로 설정하면 잠금 에스컬레이션 임계값은 locks 옵션 값의 40%이고 메모리가 가중되는 경우에는 40% 미만입니다.
데이터베이스 엔진은 에스컬레이션을 수행하기 위해 모든 세션에서 모든 활성 문을 선택할 수 있으며 인스턴스에 사용된 잠금 메모리가 임계값보다 높게 유지되는 경우에는 1,250개의 새 잠금마다 에스컬레이션을 수행할 문을 선택합니다.
<SQL Server 2008 – 잠금 에스컬레이션>
데이터베이스 엔진 인스턴스의 에스컬레이션 임계값
잠금 수가 잠금 에스컬레이션에 대한 메모리 임계값보다 커지면 데이터베이스 엔진에서 잠금 에스컬레이션을 트리거합니다. 메모리 임계값은 다음과 같은 locks 구성 옵션의 설정에 따라 다릅니다.
l locks 옵션을 기본값인 0으로 설정하면 잠금 개체에서 사용하는 메모리가 AWE 메모리를 제외하고 데이터베이스 엔진에서 사용하는 메모리의 40%일 때 잠금 에스컬레이션 임계값에 도달합니다. 잠금을 나타내는 데 사용되는 데이터 구조의 길이는 약 100바이트입니다. 데이터베이스 엔진이 다양한 작업에 맞추어 동적으로 메모리를 획득하거나 해제하기 때문에 이 임계값은 동적입니다.
l locks 옵션을 0 이외의 값으로 설정하면 잠금 에스컬레이션 임계값은 locks 옵션 값의 40%이고 메모리가 가중되는 경우에는 40% 미만입니다.
데이터베이스 엔진은 에스컬레이션을 수행하기 위해 모든 세션에서 모든 활성 문을 선택할 수 있으며 인스턴스에 사용된 잠금 메모리가 임계값보다 높게 유지되는 경우에는 1,250개의 새 잠금마다 에스컬레이션을 수행할 문을 선택합니다.
http://msdn.microsoft.com/ko-kr/library/ms175978.aspx
송 혁, SQL Server MVP
sqler.pe.kr // sqlleader.com
hyoksong.tistory.com
"SQL Server 2008의 새로운 기능 - part 1.pdf"
SQL Server 2008의 새로운 기능중에 하나인 XEVENT로 CHECKPOINT에 따른 쿼리 응답시간 영향에 대해 적어보았습니다.
참고하세요~
송 혁, SQL Server MVP
sqler.pe.kr // sqlleader.com
hyoksong.tistory.com // nexondbteam.tistory.com
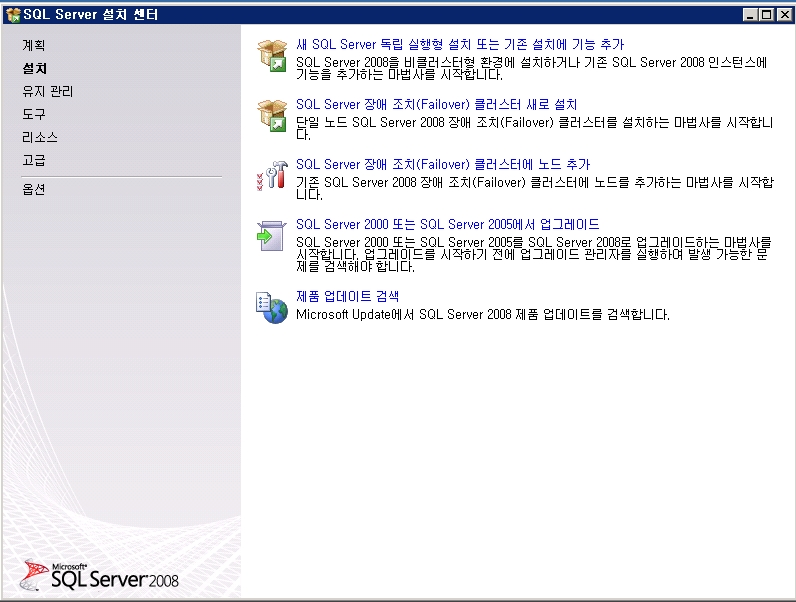
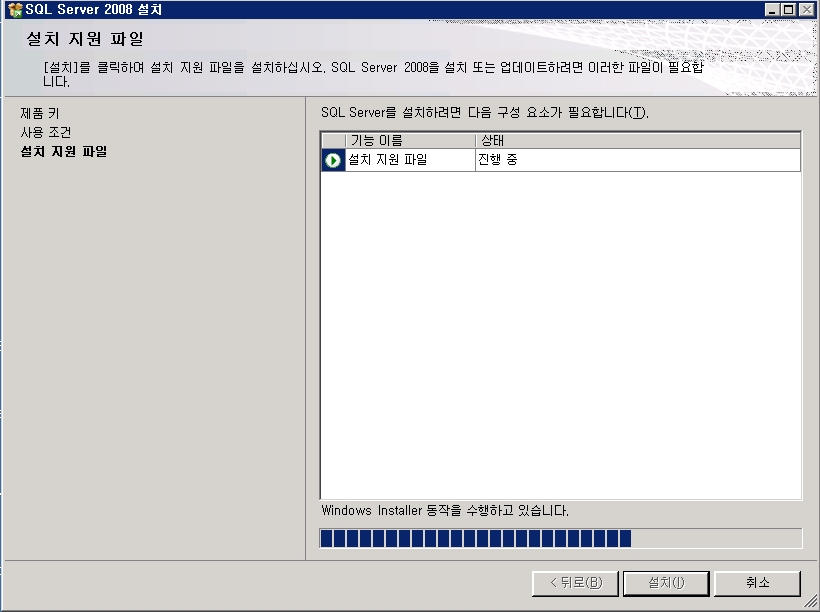
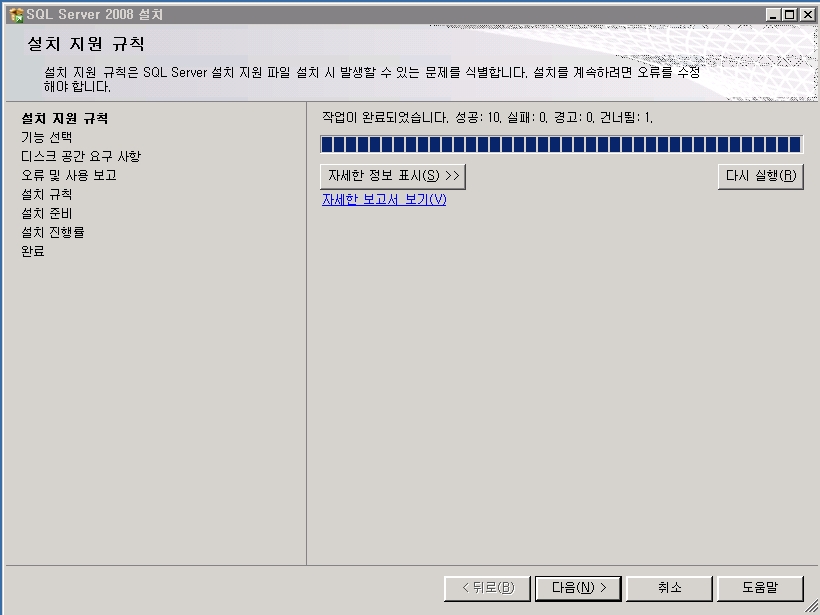
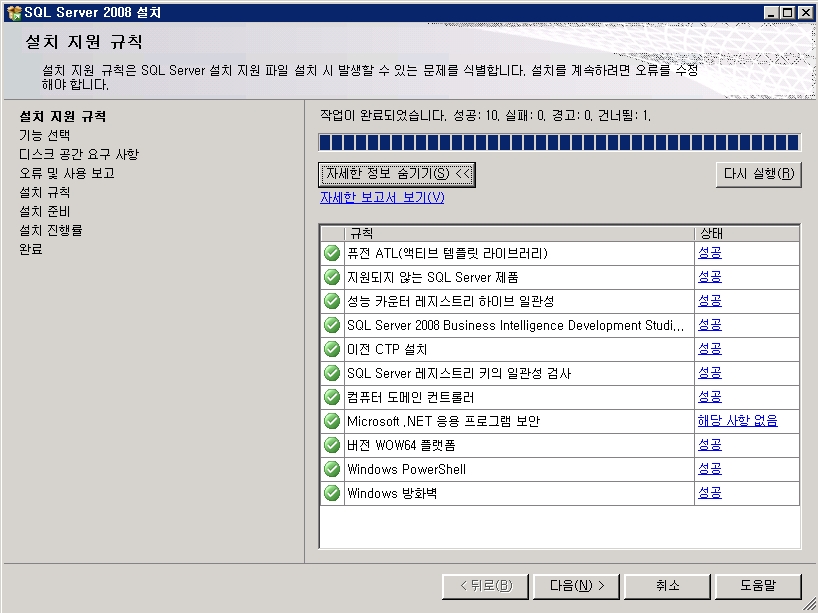
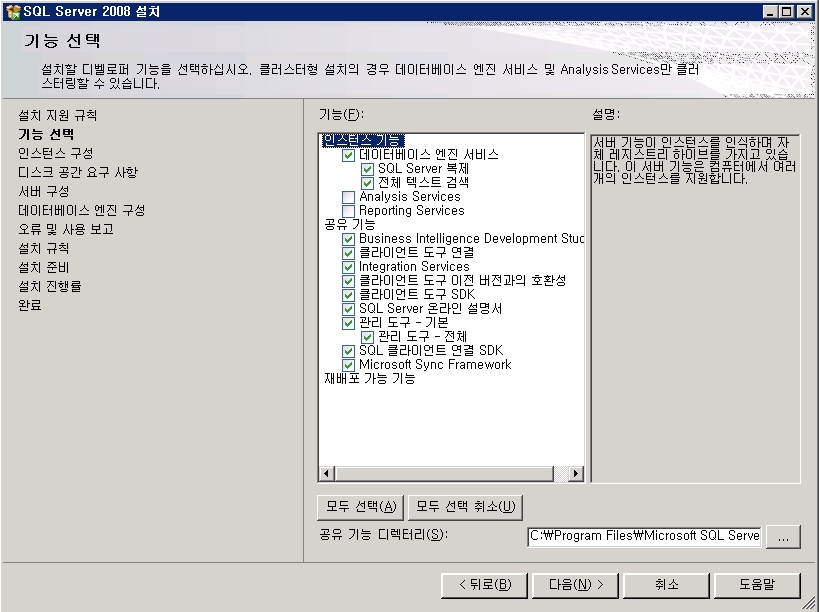
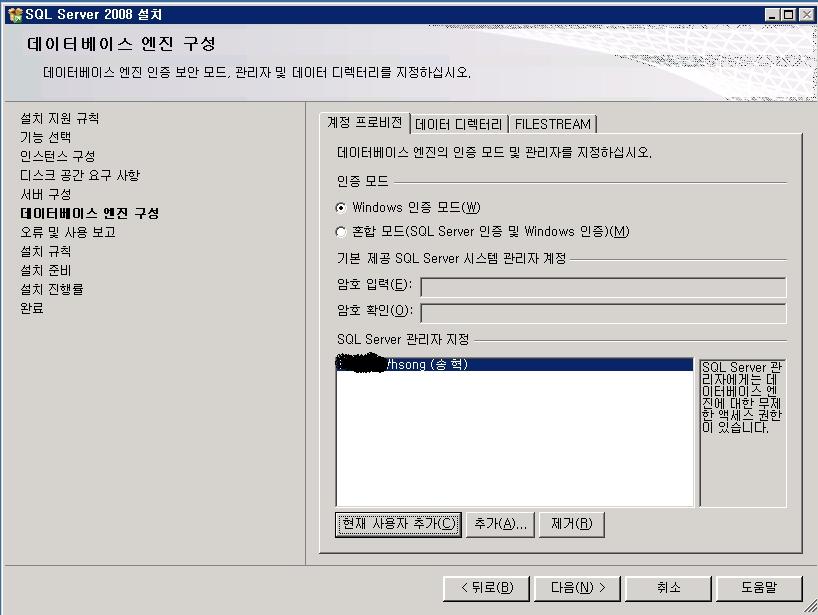
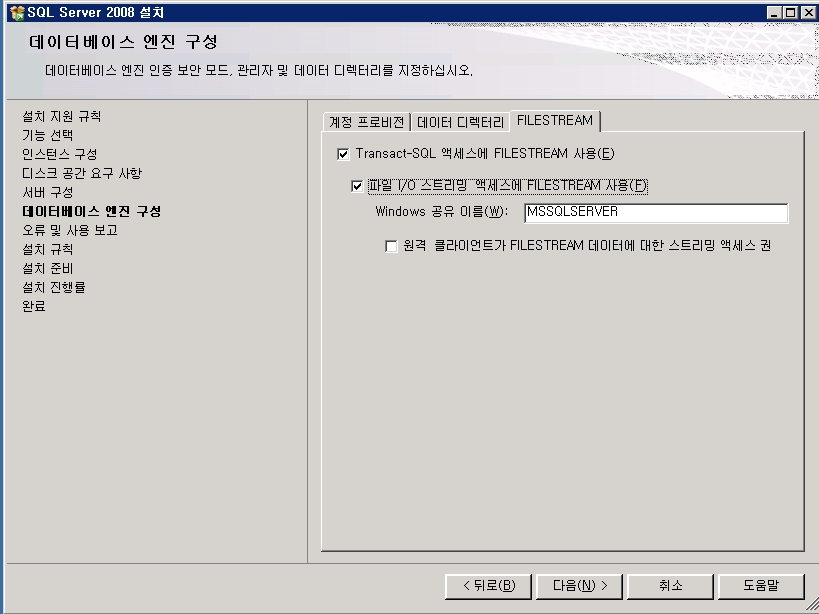
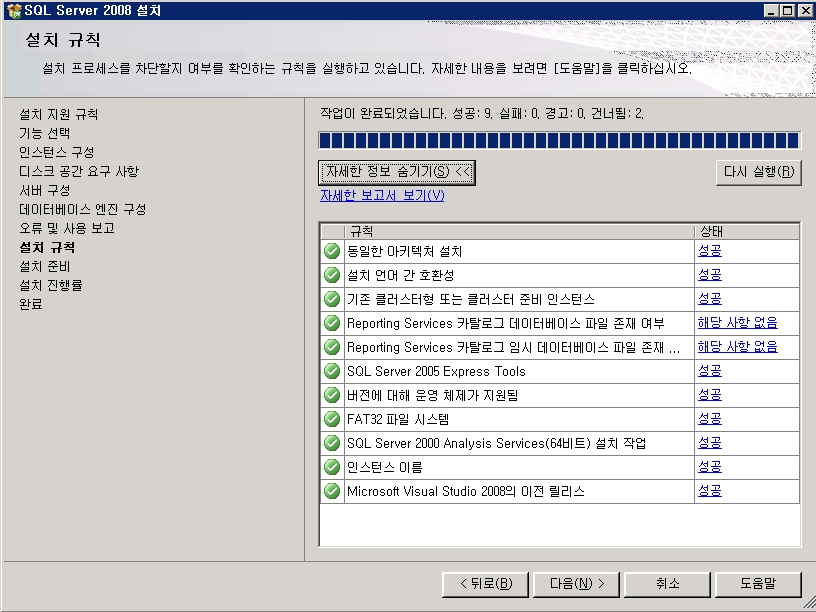
기념으로 설치 과정을 포스팅해 봅니다.ㅎㅎ
설치 하는 부분도 이전 버전보다 전체적으로 나아진 느낌이고
전체적으로 깔끔 하네요~
송 혁, SQL Server MVP
sqler.pe.kr // sqlleader.com
hyoksong.tistory.com // nexondbteam.tistory.com
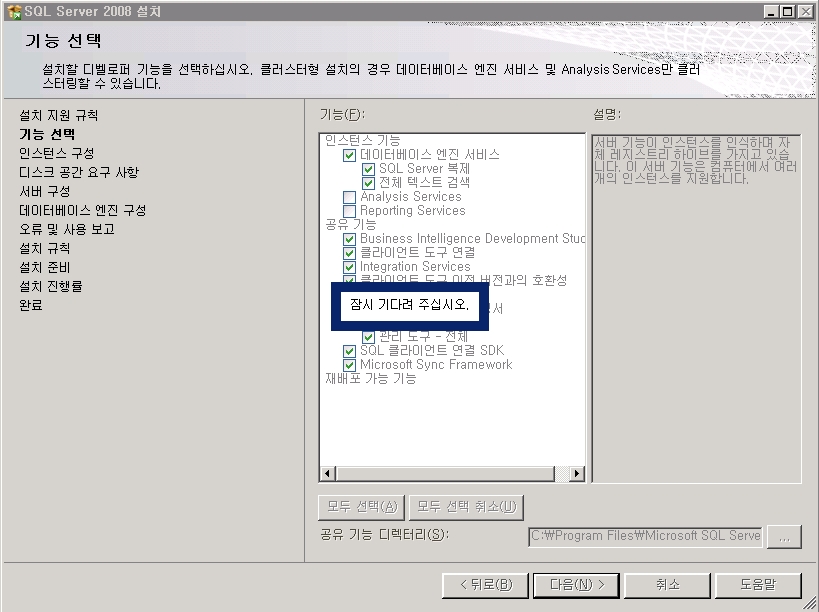
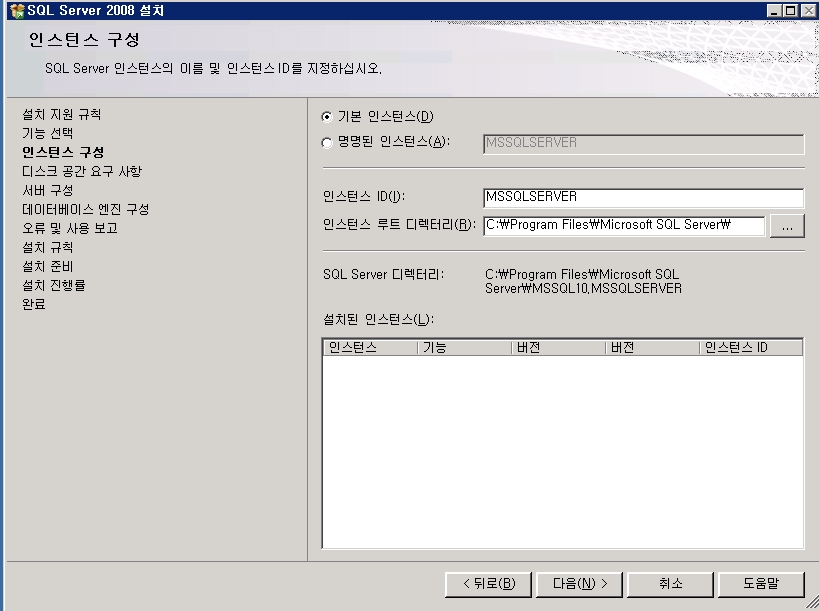
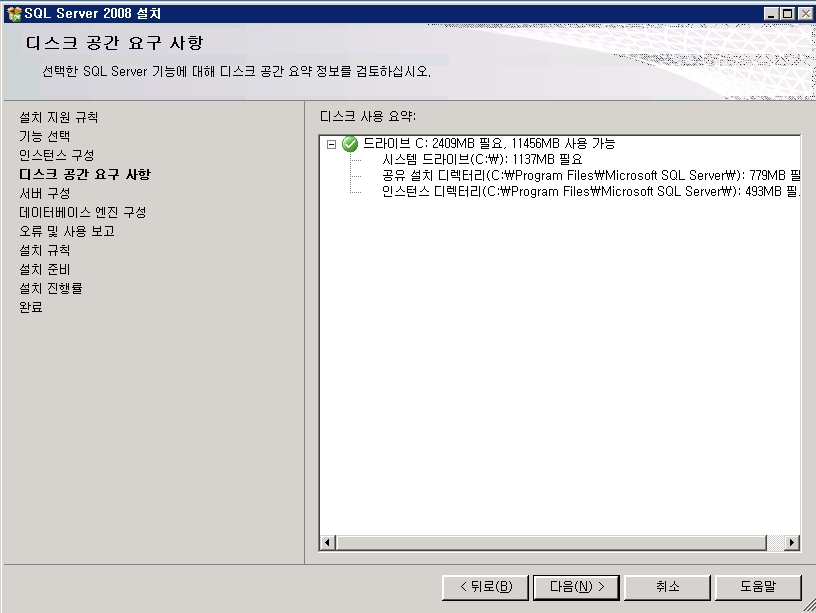
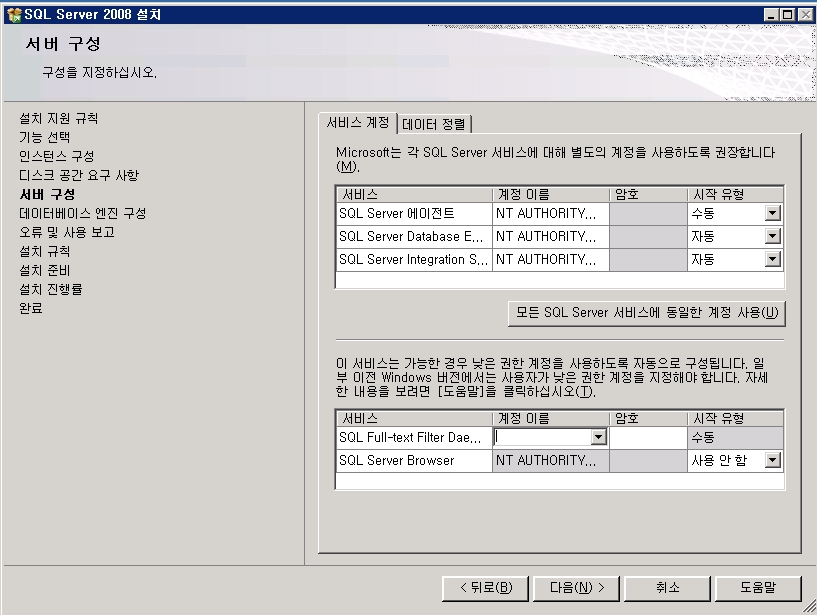
요즘 이리저리..정신 없는 날 들의 연속이라...
포스팅을 제대로 못하고 있네요...
이번에 적어본 내용은 SQL Server 2008의 새로운 기능에 대한 .. DW환경에서의 이점을 줄 수 있는..
쉽게 읽어볼 수 있는 주제인듯 합니다.
제목 : SQL Server 2008의 새로운 기능 - Star Join query optimization(multiple bitmap filters)
많은 DW 시스템은 Star 스키마로 구성 되어있으며, 이러한 스타 스키마로 구성된 대량의 팩트 테이블과 많은 차원 테이블에 대해서 데이터를 검색 하기 위해서는 많은 리소스 및 시간이 소요 됩니다.
이러한 많은 시간과 리소스에 대해서 어느 정도의 보완점이 될 수 있는 기능으로써 SQL Server 2008에서 새로운 기능으로 Star join query optimization을 지원하고 있습니다.
SQL Server 2008에서 Star Join이 추가된다고 해서 특별히 다른 물리연산자가 추가된 것은 아니며, 추가된 구문도 있지 않습니다.
여기서는 이 기능에 대해서 SQL Server 2005와 비교하여 실행계획이 어떻게 변경이 되었는지 확인해 보려고 합니다.
그리고!! 중요한 것은 Enterprise Edition에서만 지원합니다.
BOL에서는 Star join query optimization에 대해서 “비트맵 필터링을 통한 데이터 웨어하우스 쿼리 성능 최적화” 라는 제목으로 소개를 하고 있습니다.
비트맵은 SQL Server 2008 이전에도 존재했던 물리 연산자 이며 병렬 Hash, Merge 연산자에서만 사용될 수 있는 연산자 입니다.
그리고 SQL Server 2008에서 지원한다는 Star Join 쿼리 향상도 비트맵 연산자를 통해서 처리되고 있습니다.
그렇다면 기존에도 있는 연산자인데 왜!! 무엇을 지원한다는 것일까요?
SQL Server 2005 플랜과 2008플랜으로 무엇이 변경이 되었는지 아래에서 살펴보도록 하겠습니다.
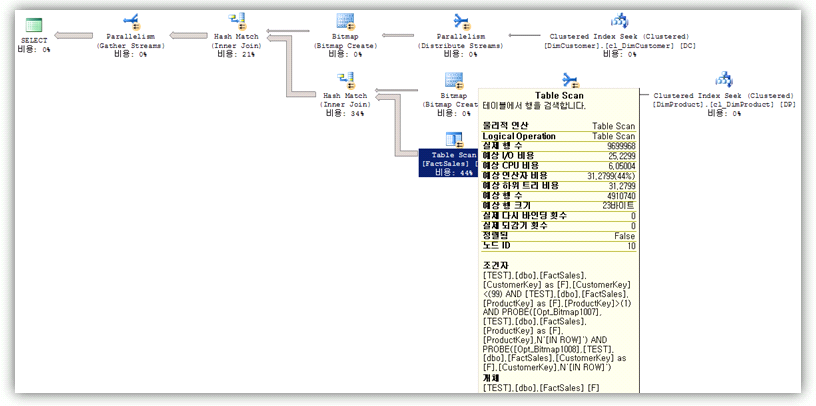
아래는 SQL Server 2005의 실행 계획이며, 하나의 팩트 테이블과 두 개의 차원테이블을 조인한 실행 계획입니다.
우선 DimCustomer 테이블을 읽어서 비트맵을 생성합니다.
그리고 DimProduct 테이블을 읽어서 비트맵을 생성하고 팩트 테이블을 읽어 병렬연산자(Repartition Streams)에서 위 DimProduct에서 생성된 비트맵을 바탕으로 필터조건을 주어 데이터 양을 줄이는 것을 볼 수 있습니다.
왜? 위에서 만든 DimCustomer의 비트맵도 같이 필터 조건을 주어 처리하면 처음부터 보다 적은 데이터 양으로 처리 할 수 있을 것인데, 왜 하나의 비트맵만..사용했을까요?
그럼 아래 SQL Server 2008의 실행계획을 보도록 하겠습니다.
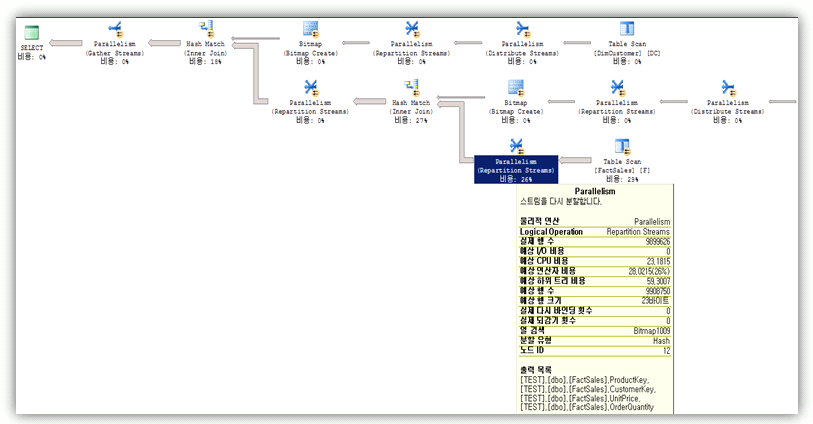
위 2005 플랜과 유사한 모습이며 여기서도 DimCustomer, DimProduct 테이블에 대해서 비트맵을 생성하는 것을 볼 수 있습니다.
하지만 팩트 테이블 스캔 연산자에서 “조건자” 부분을 보시면 위에서 생성된 비트맵 두 개를 가지고 테이블 스캔시에 필터를 하는 것을 확인 할 수 있습니다.
위 플랜과 차이점은 두 개 이상의 비트맵에 대해서 테이블 스캔시 Bitmap을 기반으로 필터를 하는 것입니다.
SQL Server 2005의 경우에는 하나의 비트맵으로 병렬연산자(Repartition Streams)에서 필터 조건을 주었습니다.
테이블 스캔시 필터를 하고, 여러 비트맵을 가지고 처리하기에 위 SQL Server 2005보다 좋은 성능을 가져올 수 있을 것 입니다.
PROBE([Opt_Bitmap1007],[TEST].[dbo].[FactSales].[ProductKey] as [F].[ProductKey],N'[IN ROW]') AND PROBE([Opt_Bitmap1008],[TEST].[dbo].[FactSales].[CustomerKey] as [F].[CustomerKey],N'[IN ROW]')
sqler.pe.kr
sqlleader.com
hyoksong.tistory.com
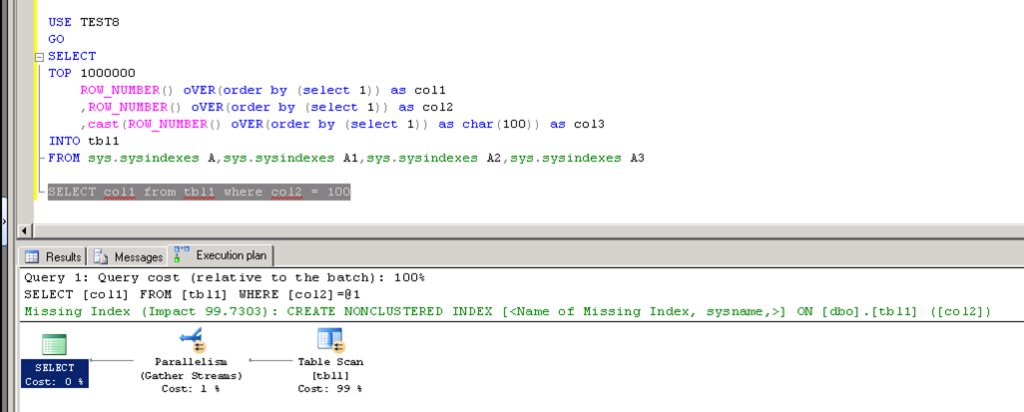
인덱스가 제대로 구성되지 않은 쿼리를 실행하면 아래와 같이 missing index라고 해서
현재 이 쿼리에 필요한 인덱스를 추천 해 주는 기능을 제공합니다.
sqler.pe.kr // sqlleader.com
hyoksong.tistory.com // nexondbteam.tistory.com