



플래터가 물리적으로 움직이는 기존의 디스크 보다 적은 전력, 적은 소음, 빠른 성능을 장점으로 내세우며 많은 이슈가 되고 있는 SSD에 대해서 간단한 성능 테스트를 하였습니다.
CPU 및 메모리는 날이 갈수록 고 클럭으로 발전하지만, 디스크는 15Krpm이 나온지 오래 되었지만 아직도 비슷한 스펙의 디스크를 사용하고 있습니다.
아직까지는 SSD의 GB당 가격이 비싸기에 대중적으로 사용하고 있지는 않지만, 조만간 대중적으로 사용할 제품이라고 생각되며, DB시스템 환경에서 하드웨어 리소스 중 가장 많이 문제가 되는 것 중에 하나인 IO 문제를 해결할 수 있는 가장 좋은 대안이라고 생각됩니다.
다행히 예전부터 계속 써보고 싶던 SSD를 거북엄마님께서 1달간 대여해주셔서 관련 테스트를 해볼 수 있게 되었습니다.
(감사합니다. 잘 써서 무사히 돌려 보내겠습니다.)
서버에서 사용하는 컨트롤러가 아닌 일반 PC의 보드 내장 컨트롤러이기에 테스트 결과 중 일부는 잘못될 수도 있습니다.
아래는 테스트한 SSD 생산 업체에서 제공하는 스펙입니다.
랜덤 IOPS가 16000정도에 달하며, 응답시간은 0.1msec라고 합니다.
보통의 15K 디스크가 300정도의 IOPS를 보여주는 것에 비교하면 대략 50배 이상 성능이 좋은 것을 볼 수 있습니다.
또한 응답시간이 1msec도 안 걸리 것도 SSD만의 장점이라고 볼 수 있습니다.

그럼 과연 어느 정도의 속도를 보여줄 지 Microsoft에서 제공하는 SQLIO라는 IO성능 도구로 테스트 하였습니다.
테스트는 총 4가지로 하였습니다.
- 랜덤 8KB 읽기 (thread 2 / outstanding 4)
- 랜덤 8KB 쓰기 (thread 2 / outstanding 4)
- 순차 1024KB 읽기 (thread 2 / outstanding 4)
- 순차 1024KB 쓰기 (thread 2 / outstanding 4)
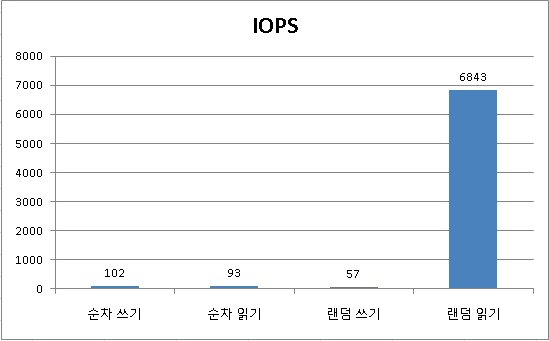
테스트 결과는,
순차 읽기, 쓰기 작업은 100 IOPS 즉 초당 전송속도가 100MB정도입니다.
위 스펙에서 보여지고 있는 수치와 동일한 것을 알 수 있습니다.
하지만 중요한 건 랜덤IO 작업입니다. OLTP환경에서는 대부분의 IO가 랜덤으로 동작하게 됩니다.
물론 Write Cache를 지원하는 컨트롤러를 사용하게 되면 어느 정도 랜덤 쓰기 작업을 순차 작업으로도 변경가능하긴 합니다.
아무튼 이러한 외부 요인을 생각하지 않는다면 DB시스템에서 사용하기에 조금 무리가 있는 결과를 보여주었습니다.
랜덤 읽기의 경우 대략 6800 IOPS를 보여주고 있습니다. 스펙보다는 적지만 일반 디스크 수십 장으로 구성하여야지만 나타낼 수 있는 성능입니다.
하지만 랜덤 쓰기 IOPS의 경우 57을 보여주고 있습니다. 테스트한 제품이 SLC기반의 SSD이기에 쓰기 작업도 좋은 성능을 보여줄 것이라고 판단하였지만 예상과는 전혀 다른 결과를 보여주었습니다.
서버에서 사용하는 컨트롤러를 사용하였다면 다른 결과를 보여줄 수 있겠지만, 아래의 데이터만 본다면
일반적인 OLTP환경에서는 약간 쓰기가 부담스러워 보입니다.
EMC, 최근에는 HP에서도 SAN제품에 SSD를 장착 할 수 있는 제품을 발표하였고, 점점 SSD가격도 내려가고 있습니다.
몇 년 후면 지금 보다 더욱 빠른 SSD를 사용하는 DB가 많아질 것 입니다.
그런 날이 빨리 오기를 기대해 봅니다.
sqler.pe.kr // sqlleader.com
hyoksong.tistory.com
SQL Server 2005 이상 버전에서는 아래의 DMV를 통하여 어떠한 테이블에 인덱스가 없어 성능적으로 영향을 주는지 확인 할 수 있습니다.
sys.dm_db_missing_index_groups
sys.dm_db_missing_index_group_stats
sys.dm_db_missing_index_details
또한 예전에 소개하였듯이 SQL Server 2008에서는 그래픽 실행계획에서 missing index에 대한 정보도 바로 확인 할 수 있습니다.
하지만 여전히 missing index로 잡히게 한 쿼리의 원본은 쉽게 확인 할 수가 없습니다.
그래서 이번에 소개하는 내용은 조금 더 쉽게 missing index를 유발한 쿼리를 찾아보는 것입니다.
XML 실행계획에 이 missing index에 대한 정보도 같이 저장 되어있기에 전에 소개했던 DMV를 조금 응용하면 특정 테이블에 어떤 쿼리로 인해 missing index가 등록되었는지 쉽게 확인 할 수 있을 것입니다.
자세한 내용은 아래를 참고하세요.
with XMLNAMESPACES ('http://schemas.microsoft.com/sqlserver/2004/07/showplan' as sql)
SELECT --TOP 10
db_name
,sp_name
,sp_text
,[statement_text]
,X.*
,[creation_time]
,[ExecutionCount]
FROM
(
SELECT
db_name(qt.dbid) AS 'db_name'
,qt.text AS 'sp_text'
, substring(qt.text, (qs.statement_start_offset/2)+1
, ((case qs.statement_end_offset
when -1 then datalength(qt.text)
else qs.statement_end_offset
end - qs.statement_start_offset)/2) + 1) as statement_text
, qs.creation_time
, qs.execution_count AS 'ExecutionCount'
, cast(qp.query_plan as xml) as query_plan
,OBJECT_NAME(qp.objectid,qp.dbid) as sp_name
FROM sys.dm_exec_query_stats AS qs
CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) AS qt
CROSS APPLY sys.dm_exec_text_query_plan(qs.plan_handle,qs.statement_start_offset,qs.statement_end_offset) qp
)Y
CROSS APPLY
(
SELECT
c.value('(./@Impact)[1]','float') as missing_index_Impact
,c.value('(./sql:MissingIndex/@Database)[1]','varchar(100)') + '.'+
c.value('(./sql:MissingIndex/@Schema)[1]','varchar(100)') + '.'+
c.value('(./sql:MissingIndex/@Table)[1]','varchar(100)') as [missing_index_Table]
FROM Y.query_plan.nodes('//sql:MissingIndexGroup')B(C)
)X

sqler.pe.kr // sqlleader.com
hyoksong.tistory.com
얼마전에는 캐시된 SP의 XML플랜을 기반으로 컴파일 정보 확인 하는 것을 소개하였습니다.
이번에도 XML플랜을 이용하여 캐시된 플랜 중 FULL SCAN 하는 SP를 찾는 방법에 대해 소개합니다.
[성능 모니터 – FULL Scans/Sec]
위와 같이 운영하고 있는 서버에서 많은 FULL SCAN 수치가 보인다면,
해당 서버는 성능적으로 문제가 발생할 가능성이 있다고 생각해 볼 수 있습니다.
그렇다면 빠르고 쉽게 FULL SCAN하는 쿼리를 찾아 수정 하여야 할 것 입니다.
하지만, 기본적인 DMV로는 인덱스에 대한 SCAN 수에 대해서는 확인 할 수 있지만, SP에 대해서는 SCAN 여부 조차 확인 할 수 없습니다.
그래서 DMV로 확인 할 수 있는 XML플랜을 XQUERY를 사용하여 찾아보는 쿼리를 만들어 보았습니다.
with XMLNAMESPACES ('http://schemas.microsoft.com/sqlserver/2004/07/showplan' as sql)
SELECT * FROM
(
SELECT
db_name(qt.dbid) AS 'DB Name'
,qt.dbid
,OBJECT_NAME(qp.objectid,qp.dbid) as sp_name
,qt.text AS 'sp_text'
, substring(qt.text, (qs.statement_start_offset/2)+1
, ((case qs.statement_end_offset
when -1 then datalength(qt.text)
else qs.statement_end_offset
end - qs.statement_start_offset)/2) + 1) as statement_text
, qs.creation_time
, qs.execution_count AS 'Execution Count'
, ISNULL(qs.execution_count/DATEDIFF(Second, qs.creation_time, GetDate()), 0) AS 'Calls/Second'
, DATEDIFF(Minute, qs.creation_time, GetDate()) AS 'Age in Cache'
, ISNULL(qs.total_elapsed_time/qs.execution_count, 0) AS 'AvgElapsedTime(㎲)'
, qs.total_elapsed_time/1000.0/1000.0 AS 'TotalElapsedTime(sec)'
, max_elapsed_time /1000.0 AS 'maxelapsedTime(ms)'
, qs.total_worker_time/qs.execution_count AS 'AvgWorkerTime(㎲)'
, qs.total_worker_time AS 'TotalWorkerTime(㎲)'
, max_worker_time as 'max_worker_time(㎲)'
, ISNULL(qs.total_logical_reads/qs.execution_count, 0) AS 'AvgLogicalreads'
, total_logical_reads
, qs.max_logical_reads
, ISNULL(qs.total_physical_reads/qs.execution_count, 0) AS 'AvgphysicalReads'
, total_physical_reads
, qs.max_physical_reads
, ISNULL(qs.total_logical_writes/qs.execution_count, 0) AS 'AvglogicalWrites'
, qs.total_logical_writes
, qs.max_logical_writes
,text
,cast(query_plan as xml) as query_plan
FROM sys.dm_exec_query_stats as qs
CROSS APPLY sys.dm_exec_sql_text(plan_handle) as qt
CROSS APPLY sys.dm_exec_text_query_plan(qs.plan_handle,qs.statement_start_offset,qs.statement_end_offset) qp
)Y
CROSS APPLY
(
SELECT
c.value('(./@PhysicalOp)[1]','varchar(100)') as PhysicalOp
FROM Y.query_plan.nodes('//sql:RelOp')B(C)
)X
where PhysicalOp IN ('Table Scan','Index Scan')and
Y.dbid not in (1,2,3,4,32767)
[결과]

sqler.pe.kr // sqlleader.com
hyoksong.tistory.com
현재 운영중인 서버에서 쿼리별 컴파일에 사용된 리소스 및 시간을 알 수 있는 방법은 SET STATISTICS TIME 옵션과 XML 플랜이 있습니다.
위 방법을 가지고 하나씩 관련 정보를 가져오기 위해서는 꽤 긴 시간이 필요 할 수도 있습니다.
보다 쉬운 방법으로는 DMV를 이용하는 것입니다.
SQL Server 2005이상에서는 DMV를 통해 XML 플랜을 제공해주고 있습니다.
XML 플랜을 XQUERY로 표 형태로 처리한다면 보다 쉽게 컴파일에 리소스 사용에 대해 확인 할 수 있습니다.
[XML 실행계획]
|
<ShowPlanXML xmlns="http://schemas.microsoft.com/sqlserver/2004/07/showplan" Version="1.1" Build="10.0.1779.0"> <BatchSequence> <Batch> <Statements> <StmtSimple StatementText=" " StatementId="1" StatementCompId="1" StatementType="SELECT" StatementSubTreeCost="7.2111" StatementEstRows="100" StatementOptmLevel="FULL" QueryHash="0x3CFB83F9F6D5CA9A" QueryPlanHash="0x2A53000B8E4C7D2E"> <StatementSetOptions QUOTED_IDENTIFIER="true" ARITHABORT="true" CONCAT_NULL_YIELDS_NULL="true" ANSI_NULLS="true" ANSI_PADDING="true" ANSI_WARNINGS="true" NUMERIC_ROUNDABORT="false" /> <QueryPlan CachedPlanSize="80" CompileTime="53" CompileCPU="53" CompileMemory="1400"> |
쿼리 플랜에서 몇가지 속성값에 대해 간단히 정리해 보면
- CompileTime : 쿼리가 컴파일 할 때 소요된 시간 (SQL Server 2005 SP2 추가)
- CompileCPU: : 쿼리가 컴파일 할 때 사용한 CPU 시간 (SQL Server 2005 SP2 추가)
- CompileMemory : 쿼리가 컴파일 할 때 사용한 메모리 크기(SQL Server 2005 SP2 추가)
아래의 DMV를 통해 확인 할 수 있습니다.
with XMLNAMESPACES ('http://schemas.microsoft.com/sqlserver/2004/07/showplan' as sql)
SELECT TOP 10
db_name,sp_name,sp_text,[statement_text]
,[query_plan],[CompileTime(ms)],[CachedPlanSize(kb)],[CompileCPU(ms) ],[CompileMemory(kb)]
FROM
(
SELECT
db_name(qt.dbid) AS 'db_name'
,qt.text AS 'sp_text'
, substring(qt.text, (qs.statement_start_offset/2)+1
, ((case qs.statement_end_offset
when -1 then datalength(qt.text)
else qs.statement_end_offset
end - qs.statement_start_offset)/2) + 1) as statement_text
, cast(qp.query_plan as xml) as query_plan
,OBJECT_NAME(qp.objectid,qp.dbid) as sp_name
FROM sys.dm_exec_query_stats AS qs
CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) AS qt
CROSS APPLY sys.dm_exec_text_query_plan(qs.plan_handle,qs.statement_start_offset,qs.statement_end_offset) qp
)X
OUTER APPLY
(
SELECT
c.value('(./@CompileTime)[1]','INT') AS "CompileTime(ms)"
,c.value('(./@CachedPlanSize)[1]','INT') AS "CachedPlanSize(kb)"
,c.value('(./@CompileCPU)[1]','INT') AS "CompileCPU(ms) "
,c.value('(./@CompileMemory)[1]','INT') AS "CompileMemory(kb)"
FROM query_plan.nodes('//sql:QueryPlan')B(C)
)xp
[결과]

송 혁, SQL Server MVP
sqler.pe.kr // sqlleader.com
hyoksong.tistory.com
제목 : 프로시저 캐시의 특정 타입만(SQLCP) 초기화 시키자.
64bit환경에서의 native한 대용량 메모리 지원으로 프로시저 캐시 영역도 따라 늘어났습니다.
분명 이러한 변화된 부분은 이전의 32bit 환경 보다 보다 좋은 성능을 가져올 수 있게 해주었습니다.
하지만, 프로시저 캐시 크기가 증가됨에 따라 예전에 보기 힘들었던 문제가 발생할 수가 있습니다.
아래의 표로 프로시저 캐시의 공간을 계산 할 수 있습니다.
만약 8GB의 가용 메모리를 가지고 있는 SQL Server 2005 SP2 시스템인 경우 대략 3.4GB를 프로시저 캐시로 사용할 수 있습니다.
많은 ad-hoc쿼리가 발생되어 이 공간 메모리를 모두 사용하고 있고, 저장된 계획을 재사용하지 못한다면 쓸데없는 메모리 낭비 및 계속 컴파일이 발생하게 됩니다. 이것은 전체적인 시스템으로 본다면 비효율적이라고 볼 수 있습니다.
위와 같은 환경이라면 당연히 SP 등을 이용하여 컴파일된 실행계획을 가지게 모든 쿼리를 변경하는 것을 고려해야 합니다.
하지만 지금 당장 할 수 있는 작업이 아니기에, 다른 방법을 찾아봐야 합니다.
<SQL 버전별 최대 프로시저 캐시 메모리 크기 구하기>
|
SQL Server Version |
Internal Memory Pressure Indication in Cachestore |
|
SQL Server 2005 RTM & SP1 |
75% of server memory from 0-8GB + 50% of server memory from 8Gb-64GB + 25% of server memory > 64GB |
|
SQL Server 2005 SP2 |
75% of server memory from 0-4GB + 10% of server memory from 4Gb-64GB + 5% of server memory > 64GB |
|
SQL Server 2000 |
SQL Server 2000 4GB upper cap on the plan cache |
다른 방법에 대해 찾기 위해서는 우선 프로시저 캐시 저장 구조에 대해서 조금 알아 볼 필요가 있습니다. 간단하게 프로시저 캐시에 대해서 알아보도록 하겠습니다.
프로시저 캐시는 아래와 같이 4가지 타입으로 저장됩니다.
l CACHESTORE_OBJCP(Object Plans)
- SP 함수의 컴파일된 계획
l CACHESTORE_SQLCP(SQL Plans)
- prepared, ad-hoc쿼리의 컴파일된 계획
l CACHESTORE_PHDR(Bound Trees)
- 뷰, 제약조건, 기본값 등
l CACHESTORE_XPROC (Extended Stored Procedures)
- 확장 저장 프로시저
프로시저 캐시의 대부분의 용량을 차지하는것은 CACHESTORE_OBJCP 또는 CACHESTORE_SQLCP입니다. 위에서 설명하고 있듯이 CACHESTORE_OBJCP는 SP 및 함수 입니다. 즉 매번 재 컴파일을 하지 않아도 되는 계획입니다. 하지만 CACHESTORE_SQLCP의 경우 ad-hoc쿼리이기에 매번 재컴파일 할 수 있는 가능성이 매우 크게 됩니다.
대부분 프로시저 캐시가 커져서 문제가 되는 경우는 CACHESTORE_SQLCP 크기가 늘어남으로써 문제가 되고 있습니다. 그렇다면, 재컴파일도 하지 않고 적정한 크기를 가지는 CACHESTORE_OBJCP는 그냥 두고 매번 재컴파일하여 비효율 적인 CACHESTORE_SQLCP만을 프로시저 캐시에서 초기화 하는 것이 보다 효율적인 방법일 수 있습니다.
우선 서버에 타입별 프로시저 캐시 크기를 메모리 관련 DMV로 확인 할 수 있습니다.
select * from sys.dm_os_memory_clerks
where type in ('CACHESTORE_OBJCP','CACHESTORE_SQLCP')
그럼 프로시저 캐시를 초기화 하기 위해서는 DBCC FREEPROCCACHE를 사용하게 되며,

이 DBCC 구문은 모든 프로시저 캐시를 초기화 하게 됩니다.
하지만 이것은 비효율일 수 있습니다. 대부분의 메모리를 차지하고 있는건 SQLCP이고
초기화 시켜야 할 것도 SQLCP이기에, OBJCP까지 같이 초기화 되기 때문입니다.
그럼, SQLCP만 초기화 시키는 방법은?
아래를 참고 하세요.
초기화 이전에는 CACHESTORE_SQLCP의 single_pages_kb가 44088KB였으나,
DBCC FREESYSTEMCACHE 구문을 실행하면 552KB로 변경된 것을 확인 할 수 있습니다.
select * from sys.dm_os_memory_clerks
where type in ('CACHESTORE_OBJCP','CACHESTORE_SQLCP')
DBCC FREESYSTEMCACHE('SQL Plans')
select * from sys.dm_os_memory_clerks
where type in ('CACHESTORE_OBJCP','CACHESTORE_SQLCP')

다른 프로시저 캐시에 대해서도 내릴 수 있습니다.
DBCC FREESYSTEMCACHE('OBJECT Plans')
DBCC FREESYSTEMCACHE('BOUND Trees')
http://blogs.msdn.com/sqlprogrammability/archive/tags/Procedure+Cache/default.aspx
송 혁, SQL Server MVP
sqler.pe.kr // sqlleader.com
hyoksong.tistory.com
하지만, SQL Server 2008부터 sp_configure locks 옵션을 사용한다고 하더라도 서버는 어떠한 추가적인 영향을 받지 않습니다.
그리고 이후 버젼부터는 이 기능이 제거된다고 합니다.
이러한 변경으로 인해서 SQL Server 2008 버젼부터는 잠금에 대한 메모리를 조절 할 수 없으며,
잠금 에스컬레이션에 메모리 임계치 값이 이전 버젼과 달라졌습니다.
SQL Server 2005 / locks 기본값인 경우 - 메모리의 24%일 때 잠금 에스컬레이션 임계값에 도달
SQL Server 2008 / locks 기본값인 경우 - 메모리의 40%일 때 잠금 에스컬레이션 임계값에 도달
자세한 내용은 아래를 참고하세요.
<BOL에서>
이 규칙은 잠금 구성 옵션의 값을 검사합니다. 이 옵션은 사용 가능한 잠금의 최대 개수를 결정합니다. 이 옵션은 SQL Server 데이터베이스 엔진이 잠금에 사용하는 메모리 양을 제한합니다. 기본 설정은 0을 사용하면 데이터베이스 엔진이 시스템 요구 사항의 변화를 기준으로 동적으로 잠금 구조를 할당하거나 할당 취소할 수 있습니다.
잠금이 0이 아니면, 일괄 처리 작업이 중지되고, 지정된 값이 초과될 경우 "잠금 부족" 오류 메시지가 생성됩니다.
SQL Server에서 이 옵션 기능을 사용할 수 없어도 기존 스크립트과의 호환성을 위해 sp_configure 저장 프로시저에 이 옵션이 사용할 수 있습니다(설정의 영향 없음). 이 옵션으로 설정하면 대신 잠금 공간이 자동으로 할당됩니다.
.gif) 중요: 중요: |
|---|
| Microsoft SQL Server의 이후 버전에서는 이 기능이 제거됩니다. 새 개발 작업에서는 이 기능을 사용하지 말고, 현재 이 기능을 사용하는 응용 프로그램은 가능한 한 빨리 수정하십시오 |
<SQL Server 2005 – 잠금 에스컬레이션>
데이터베이스 엔진 인스턴스의 에스컬레이션 임계값
잠금 수가 잠금 에스컬레이션에 대한 메모리 임계값보다 커지면 데이터베이스 엔진에서 잠금 에스컬레이션을 트리거합니다. 메모리 임계값은 다음과 같은 locks 구성 옵션의 설정에 따라 다릅니다.
l locks 옵션을 기본값인 0으로 설정하면 잠금 개체에서 사용하는 메모리가 AWE 메모리를 제외하고 데이터베이스 엔진에서 사용하는 메모리의 24%일 때 잠금 에스컬레이션 임계값에 도달합니다. 잠금을 나타내는 데 사용되는 데이터 구조의 길이는 약 100바이트입니다. 데이터베이스 엔진이 다양한 작업에 맞추어 동적으로 메모리를 획득하거나 해제하기 때문에 이 임계값은 동적입니다.
l locks 옵션을 0 이외의 값으로 설정하면 잠금 에스컬레이션 임계값은 locks 옵션 값의 40%이고 메모리가 가중되는 경우에는 40% 미만입니다.
데이터베이스 엔진은 에스컬레이션을 수행하기 위해 모든 세션에서 모든 활성 문을 선택할 수 있으며 인스턴스에 사용된 잠금 메모리가 임계값보다 높게 유지되는 경우에는 1,250개의 새 잠금마다 에스컬레이션을 수행할 문을 선택합니다.
<SQL Server 2008 – 잠금 에스컬레이션>
데이터베이스 엔진 인스턴스의 에스컬레이션 임계값
잠금 수가 잠금 에스컬레이션에 대한 메모리 임계값보다 커지면 데이터베이스 엔진에서 잠금 에스컬레이션을 트리거합니다. 메모리 임계값은 다음과 같은 locks 구성 옵션의 설정에 따라 다릅니다.
l locks 옵션을 기본값인 0으로 설정하면 잠금 개체에서 사용하는 메모리가 AWE 메모리를 제외하고 데이터베이스 엔진에서 사용하는 메모리의 40%일 때 잠금 에스컬레이션 임계값에 도달합니다. 잠금을 나타내는 데 사용되는 데이터 구조의 길이는 약 100바이트입니다. 데이터베이스 엔진이 다양한 작업에 맞추어 동적으로 메모리를 획득하거나 해제하기 때문에 이 임계값은 동적입니다.
l locks 옵션을 0 이외의 값으로 설정하면 잠금 에스컬레이션 임계값은 locks 옵션 값의 40%이고 메모리가 가중되는 경우에는 40% 미만입니다.
데이터베이스 엔진은 에스컬레이션을 수행하기 위해 모든 세션에서 모든 활성 문을 선택할 수 있으며 인스턴스에 사용된 잠금 메모리가 임계값보다 높게 유지되는 경우에는 1,250개의 새 잠금마다 에스컬레이션을 수행할 문을 선택합니다.
http://msdn.microsoft.com/ko-kr/library/ms175978.aspx
송 혁, SQL Server MVP
sqler.pe.kr // sqlleader.com
hyoksong.tistory.com
오랜만에 Checkpoint관련 글을 포스팅합니다.
오늘 쓰려고 하는 내용은 이전에 올린 글에서 잠깐 언급 하였습니다.
Checkpoint는 인접해 있는 페이지들을 하나의 IO로 처리 할 수 있습니다.
하나의 IO로 여러 페이지를 처리하여, 보다 효율적으로 dirty page를 물리적 디스크로 플러쉬 할 수 있습니다. SQL Server 2000의 경우에는 최대 16개의 페이지 였지만 2005의 경우에는 최대 32개의 페이지를 하나의 IO로 처리 할 수 있습니다.
하지만 이렇게 32개 페이지를 하나의 IO로 플러쉬 하기 위해서는 checkpoint로 내려야 할 Dirty page가 순차적으로 존재해야 합니다. 데이터가 랜덤한 페이지상에 자주 변경되는 비즈니스라면 이러한 동작 방식이 도움을 줄 수 없을것입니다. 하지만 인접해 있는 페이지가 변경 되는 경우라면 보다 적은 Writes로 많은 페이지를 플러쉬 할 수 있을 것입니다. 하지만 인접해 있는 데이터가 변하지만 페이지 조각화로 인해 위와 같이 동작 하지 못할 수도 있습니다.
그렇다면 정말 위에서 말한것 처럼 동작하는지 테스트 하였습니다.
보다 명확하게 checkpoint의 IO양과 초당 처리속도를 확인해야 하기에 추적 플래그 3502,3504 를 사용하였으며, 데이터 변경을 하여 자동 checkpoint가 발생시에 errorlog에 있는 데이터로 비교하였습니다.
USE [master]
GO
CREATE DATABASE [test] ON PRIMARY
( NAME = N'test_Data', FILENAME = N'F:\test_Data.MDF' , SIZE = 102400KB , MAXSIZE = UNLIMITED, FILEGROWTH = 51200KB ),
FILEGROUP [test_Data1]
( NAME = N'test_Data1_01', FILENAME = N'F:\test_Data1_01.mdf' , SIZE = 5GB , MAXSIZE = UNLIMITED, FILEGROWTH = 51200KB )
,( NAME = N'test_Data1_03', FILENAME = N'G:\test_Data1_03.mdf' , SIZE = 5GB , MAXSIZE = UNLIMITED, FILEGROWTH = 51200KB )
LOG ON
( NAME = N'test_Log', FILENAME = N'E:\test_Log.LDF' , SIZE = 5GB , MAXSIZE = 2048GB , FILEGROWTH = 51200KB )
ALTER DATABASE [test] SET RECOVERY SIMPLE
use test
go
drop table tbl1
/*
테스트를 위해 하나의 페이지에 한행만 존재하도록 테이블을 만든다.
*/
SELECT
TOP 4000000
ROW_NUMBER() OVER(ORDER BY(SELECT 1)) as col1
,cast(ROW_NUMBER() OVER(ORDER BY(SELECT 1)) as char(5000)) as col2
INTO tbl1
FROM sys.sysindexes A,sys.sysindexes A1,sys.sysindexes A2,sys.sysindexes A3,sys.sysindexes A4
create unique clustered index ixa on tbl1(col1)
--sp_spaceused tbl1
정확한 테스트를 위해 기존에 BP에 있는 메모리 날리기.
*/
dbcc dropcleanbuffers
DBCC TRACEON(3504,3502,-1)
/*
순차적으로 데이터를 변경한다.
하나의 IO작업에 16개페이지(1572070/97851)를 내리는 것을 확인 할 수 있으며
초당 280메가의 Dirty page를 내리는 것을 볼수 있다.
*/
update tbl1
set col2 = newid()
where col1 < 2000000
2008-12-16 02:52:28.340 spid10s Ckpt dbid 11 started (8)
2008-12-16 02:52:28.340 spid10s About to log Checkpoint begin.
2008-12-16 02:52:28.340 spid10s Ckpt dbid 11 phase 1 ended (8)
2008-12-16 02:53:12.060 spid10s FlushCache: cleaned up 1572070 bufs with 97851 writes in 43719 ms (avoided 162901 new dirty bufs)
2008-12-16 02:53:12.060 spid10s average throughput: 280.93 MB/sec, I/O saturation: 72605
2008-12-16 02:53:12.060 spid10s last target outstanding: 1600
2008-12-16 02:53:12.060 spid10s About to log Checkpoint end.
2008-12-16 02:53:12.080 spid10s Ckpt dbid 11 complete
/*
랜덤하게 데이터를 변경한다.
하나의 IO작업에 1개페이지(147576/147573)를 내리는 것을 확인 할 수 있으며
초당 56메가의 Dirty page를 내리는 것을 볼수 있다.
*/
update tbl1
set col2 = newid()
where col1%2 = 0
2008-12-16 02:56:04.760 spid10s Ckpt dbid 11 started (8)
2008-12-16 02:56:04.760 spid10s About to log Checkpoint begin.
2008-12-16 02:56:04.760 spid10s Ckpt dbid 11 phase 1 ended (8)
2008-12-16 02:56:25.200 spid10s FlushCache: cleaned up 147579 bufs with 147573 writes in 20438 ms (avoided 1466 new dirty bufs)
2008-12-16 02:56:25.200 spid10s average throughput: 56.41 MB/sec, I/O saturation: 55153
2008-12-16 02:56:25.200 spid10s last target outstanding: 1600
2008-12-16 02:56:25.200 spid10s About to log Checkpoint end.
2008-12-16 02:56:25.200 spid10s Ckpt dbid 11 complete
위와 같은 결과를 보면, 순차적인 데이터 변경으로 발생된 dirty page가 보다 효과적으로 디스크로 플러쉬 되는 것을 확인 할 수 있습니다.
특정 테스트 환경이기에 위 테스트 결과를 절대적으로 신뢰할 수는 없습니다.
sqler.pe.kr // sqlleader.com
hyoksong.tistory.com
SQL Server에서 조각화는 크게 3가지로 구분지을 수 있습니다.
첫번째 논리적 조각화
두번째 익스텐트 조각화
세번째 물리적 조각화
논리적 조각화, 익스텐트 조각화 상태는 DBCC SHOWCONTIG 구문으로 확인 할 수 있으며,
주기적으로 인덱스 재구성 작업등으로 이러한 문제를 해결하고 있습니다.
(SQL Server 2005 이후부터는 sys.dm_db_index_physical_stats)
하지만 물리적 조각화는 확인 할 수 없기에, 많은 운용환경에서 물리적 조각화 상태에 대해 크게 고민하지 않고 사용하는 경우가 많습니다.
대부분의 OLTP환경에서는 물리적 조각화로 인한 성능 차이는 크지 않을 것입니다.
하지만 대용량의 데이터를 읽어야 하는 DW환경이라면 물리적 조각화로 인한 성능차이가
있을 것입니다.
랜덤 IO작업의 경우는 조각화로 인한 성능 차이는 순차 IO작업보다 크지 않기에,
이번에는 물리적 조각화로 인한 순차 읽기 작업을 성능 비교 하였습니다.
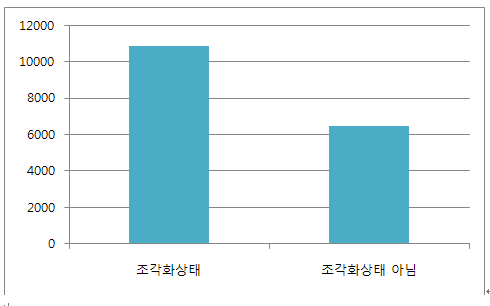
테스트 결과
조각화 상태인 경우 테이블 SCAN작업이 11초 정도 걸렸으나,
조각모음을 한 후에는 대략 6초 정도에 끝나는 것을 확인 할 수 있습니다.
이러한 편차는 환경마다 달라 질 수 있습니다
여담으로, 이론상 물리적 조각화로 인한 영향도가 전혀 없는 SSD가 많은 환경에 보급된다면
자세한건 아래 스크립트를 참고 하세요~
/*
버전
*/
select @@version
Microsoft SQL Server 2005 - 9.00.3282.00 (Intel X86)
Aug 5 2008 01:01:05
Copyright (c) 1988-2005 Microsoft Corporation
Enterprise Edition on Windows NT 5.2 (Build 3790: Service Pack 2)
/*
순차적으로 두개의 DB의 파일을 1MB 단위씩 증가 시켜 물리적 조각화 상태를 만듬
물리적 조각화가 발생
*/
DECLARE @I VARCHAR(100)
SET @I= '4'
WHILE 1=1
BEGIN
EXEC ('ALTER DATABASE TEST MODIFY FILE(NAME = ''TEST'',SIZE='+@I+')')
EXEC ('ALTER DATABASE TEST1 MODIFY FILE(NAME = ''TEST1'',SIZE='+@I+')')
SET @I=@I+1
IF @I=5000 BREAK
END
/*
테스트를 위해 4000만건 대략 5GB 정도의 데이터를 입력한다.
*/
USE TEST
GO
SELECT TOP 40000000
row_number() over(order by (select 1)) as col1
,cast('' as char(100)) col2
INTO tbl
FROM master.dbo.spt_values A,master.dbo.spt_values A1,master.dbo.spt_values A2,master.dbo.spt_values A3
/*
SHOWCONTIG를 통해 논리적 조각화 상태를 본다.
방금 만들어서, 깔끔하다!!
*/
dbcc showcontig(tbl)
/*
DBCC SHOWCONTIG scanning 'tbl' table...
Table: 'tbl' (2105058535); index ID: 0, database ID: 5
TABLE level scan performed.
- Pages Scanned................................: 579712
- Extents Scanned..............................: 72465
- Extent Switches..............................: 72464
- Avg. Pages per Extent........................: 8.0
- Scan Density [Best Count:Actual Count].......: 100.00% [72464:72465]
- Extent Scan Fragmentation ...................: 0.10%
- Avg. Bytes Free per Page.....................: 23.0
- Avg. Page Density (full).....................: 99.72%
DBCC execution completed. If DBCC printed error messages, contact your system administrator.
*/
/*
In-memory로 인해 테스트에 영향을 줄 수 있으니~ BP에 있는건 모두 날리자.
*/
exec sp_msforeachtable 'checkpoint 1'
dbcc dropcleanbuffers
--2
SET STATISTICS TIME ON
SET STATISTICS IO ON
SELECT COUNT(*) FROM tbl
SET STATISTICS TIME OFF
SET STATISTICS IO OFF
/*
처음 데이터를 SCAN(물리적 조각화 상태)
*/
Table 'tbl'. Scan count 9, logical reads 579712, physical reads 0, read-ahead reads 579647, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
CPU time = 9875 ms, elapsed time = 10829 ms.
/*
물리적 조각 모음 후
논리적 조각모음은 여전하다.
*/
dbcc showcontig(tbl)
/*
DBCC SHOWCONTIG scanning 'tbl' table...
Table: 'tbl' (2105058535); index ID: 0, database ID: 5
TABLE level scan performed.
- Pages Scanned................................: 579712
- Extents Scanned..............................: 72465
- Extent Switches..............................: 72464
- Avg. Pages per Extent........................: 8.0
- Scan Density [Best Count:Actual Count].......: 100.00% [72464:72465]
- Extent Scan Fragmentation ...................: 0.10%
- Avg. Bytes Free per Page.....................: 23.0
- Avg. Page Density (full).....................: 99.72%
DBCC execution completed. If DBCC printed error messages, contact your system administrator.
*/
Table 'tbl'. Scan count 9, logical reads 579712, physical reads 0, read-ahead reads 579327, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
CPU time = 10922 ms, elapsed time = 6452 ms.
sqler.pe.kr // sqlleader.com
hyoksong.tistory.com
SQL 2000,2005,2008 버젼을 지원합니다.
자세한 내용은 아래 블로그를 참조 하세요
http://blogs.msdn.com/psssql/archive/2008/11/12/cumulative-update-1-to-the-rml-utilities-for-microsoft-sql-
server-released.aspx
아래 링크에서 다운 받을 수 있습니다.
RML Utilities for SQL Server (x86)
http://www.microsoft.com/downloads/details.aspx?FamilyID=7edfa95a-a32f-440f-a3a8-5160c8dbe926
RML Utilities for SQL Server (x64)
http://www.microsoft.com/downloads/details.aspx?FamilyID=b60cdfa3-732e-4347-9c06-2d1f1f84c342
송 혁, SQL Server MVP
sqler.pe.kr // sqlleader.com
hyoksong.tistory.com
요즘 출시되는 인텔의 제온, AMD의 옵테론 프로세스는 64bit(x64)를 기본적으로 지원되고 있고 있으며, SQL Server도 2005부터는 x64 를 지원하고 있습니다.(IA64는 SQL Server 2000도 지원함)
기존 x86의 AWE메모리의 한계와 IA64 도입에 대한 높은 도입 비용으로 인해 x64 환경이 점차 늘어나고 있는 상황입니다.
32bit에서 4GB이상의 메모리를 사용하기 위해서는 AWE 옵션을 Enable해서 64GB까지 사용할 수 있지만,
AWE로 확장된 메모리 영역은 데이터&인덱스 페이지로만 구성되기에 다른 영역의 메모리는 기존처럼 2GB(/3GB 추가시 3GB) 공간만을 사용할 수 밖에 없습니다.
AWE에서 확장된 메모리를 map, unmap을 하기 위한 Window도 이 2GB에 포함되기에 잠금, 플랜 캐쉬, 연결, 쓰레드 스택에 대해 메모리 부족현상이 발생할 수 있습니다.
이러한 x86의 한계를 근본적으로 해결해 줄 수 있는 것이 64bit 시스템입니다.
또한 x64의 경우는 IA64보다 현저히 저렴하게 구성할 수 있기에 적은 투자비용으로 위와 같은 문제를 해결 할 수 있습니다.
기존의 여러 개의 SQL Server 2000으로 구성된 DB를 메모리 제한이 없는 SQL server 2005 x64 standard edition으로 Scale-up을 계획하시거나 사용 중이시라면 주의하게 살펴봐야 할 것 중에 하나는 바로 “Lock pages in memory” 정책의 활성화 여부입니다.
즉 Standard edition(x64) 은 “Lock pages in memory” 정책을 지원하지 않습니다.(x86 Standard는 “Lock pages in memory” 정책 지원함)
이 정책이 뭐길래~ edition에 따라 지원 여부가 달라질까요?
BOL에서는 Lock pages in memory 정책을 아래와 같이 설명 하고 있습니다.
|
이 정책은 데이터를 실제 메모리에 유지하는 프로세스를 사용하여 시스템이 디스크의 가상 메모리로 데이터를 페이징하지 않도록 방지할 수 있는 계정을 결정합니다. SQL Server에서는 Lock Pages in Memory 옵션이 기본적으로 OFF로 설정됩니다. 시스템 관리자 권한이 있으면 Windows 그룹 정책 도구(gpedit.msc)를 사용하여 수동으로 옵션을 설정하고 SQL Server가 실행 중인 계정에 이 사용 권한을 할당할 수 있습니다. Lock Pages in Memory 옵션을 설정하는 방법은 방법: Lock Pages in Memory 옵션 설정(Windows)을 참조하십시오. 반드시 필요한 것은 아니지만 64비트 운영 체제를 사용하는 경우 메모리의 페이지를 잠그는 것이 좋습니다. 32비트 운영 체제의 경우 SQL Server에 맞게 AWE를 구성하기 전에 Lock pages in memory 권한을 얻어야 합니다. |
x64환경에서 제공하는 거의 무한대의 VAS영역으로 인해서 프로세스의 Working Set이 paged out될 가능성이 x86환경보다 높습니다.
그리고 이러한 paged out이 SQL Server서비스가 올라가 있는 장비에서 발생한다면 SQL Server는 아래와 같은 메시지와 함께 성능적인 문제가 발생할 것입니다.
Enterprise edition이라면 이 정책을 사용하여 문제를 해결 할 수 있지만, Standard edition에서는 이러한 문제가 발생할 경우 이 정책을 사용할 수 없게 되어서 문제가 될 수 있습니다.
이러한 문제가 발생 할 가능성이 있다면 도입 전 테스트 등의 확인 작업이 필요할 것으로 보입니다.
2008-08-08 13:53:56.240 spid1s A significant part of sql server process memory has been paged out. This may result in a performance degradation. Duration: 337 seconds. Working set (KB): 2393904, committed (KB): 6292600, memory utilization: 38%.
2008-08-08 13:58:23.660 spid1s A significant part of sql server process memory has been paged out. This may result in a performance degradation. Duration: 604 seconds. Working set (KB): 2844740, committed (KB): 6292344, memory utilization: 45%.
송 혁, SQL Server MVP
sqler.pe.kr // sqlleader.com
hyoksong.tistory.com // nexondbteam.tistory.com