



"SQL Server 2008의 새로운 기능 - part 1.pdf"
SQL Server 2008의 새로운 기능중에 하나인 XEVENT로 CHECKPOINT에 따른 쿼리 응답시간 영향에 대해 적어보았습니다.
참고하세요~
송 혁, SQL Server MVP
sqler.pe.kr // sqlleader.com
hyoksong.tistory.com // nexondbteam.tistory.com
아래 링크를 보시면 여러 백서(한글화된 것도 꽤있더라구요) 및 도움 될만한 정보를 얻을 수 있습니다.
백서의 경우 간단하게 하나의 압축 파일로 받으시려면 중간쯤에 있는 Start Pack 다운받기 배너를
통해 한방에 받으실 수 있습니다.
http://www.microsoft.com/korea/sqlserver/2008/default.aspx

송 혁, SQL Server MVP
sqler.pe.kr // sqlleader.com
hyoksong.tistory.com // nexondbteam.tistory.com
기념으로 설치 과정을 포스팅해 봅니다.ㅎㅎ
설치 하는 부분도 이전 버전보다 전체적으로 나아진 느낌이고
전체적으로 깔끔 하네요~
송 혁, SQL Server MVP
sqler.pe.kr // sqlleader.com
hyoksong.tistory.com // nexondbteam.tistory.com
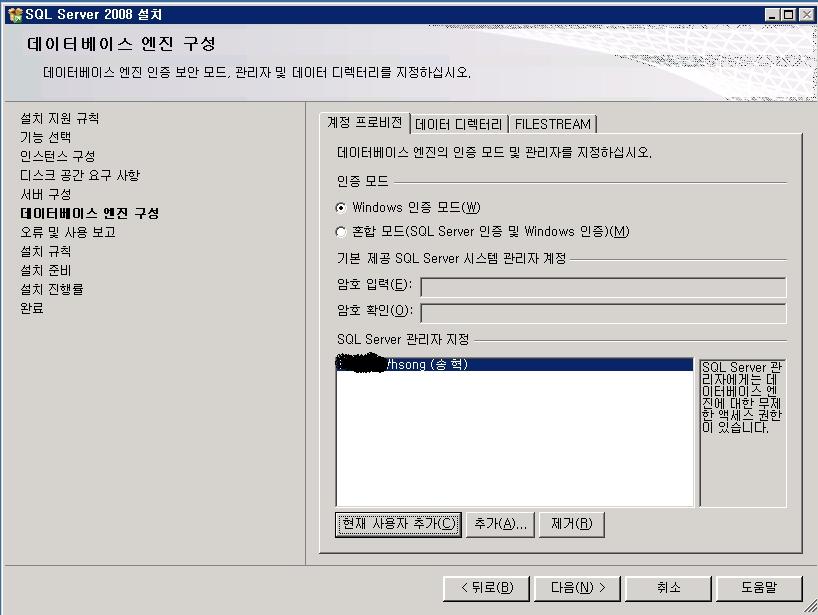
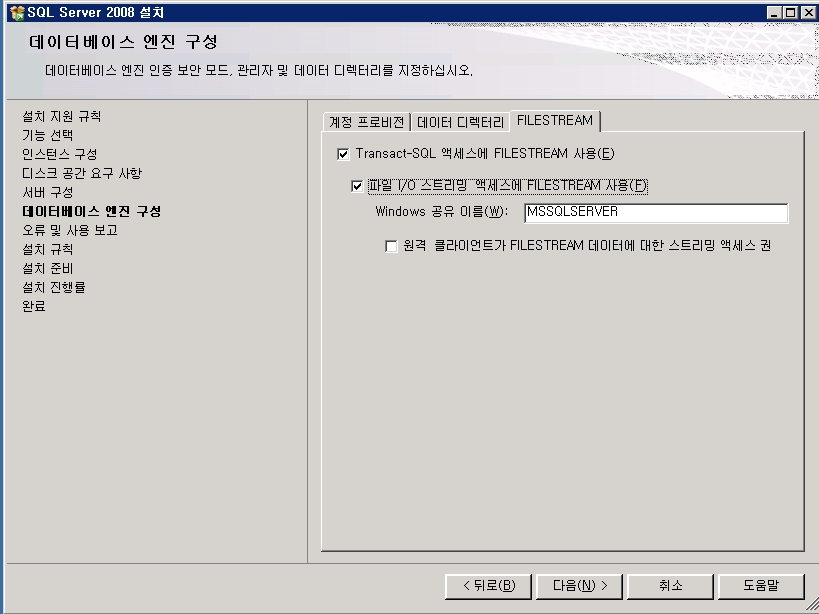
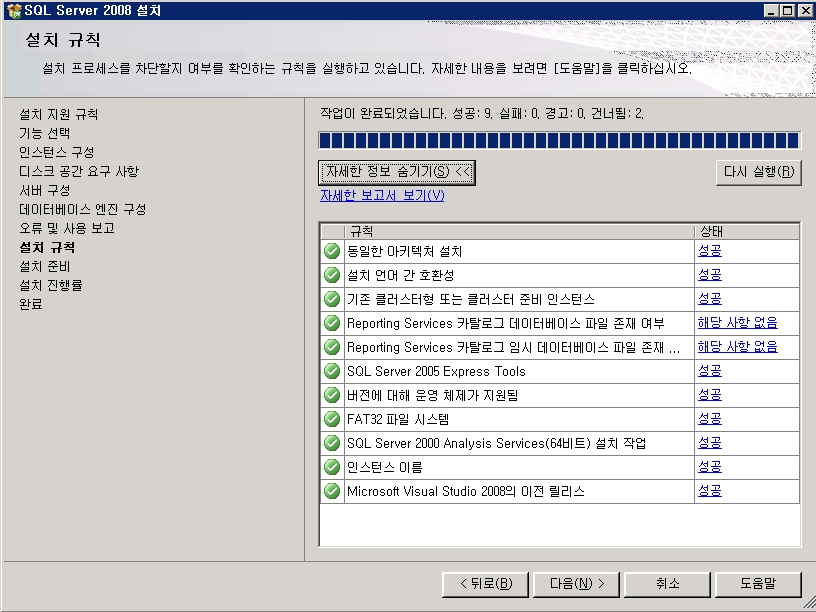
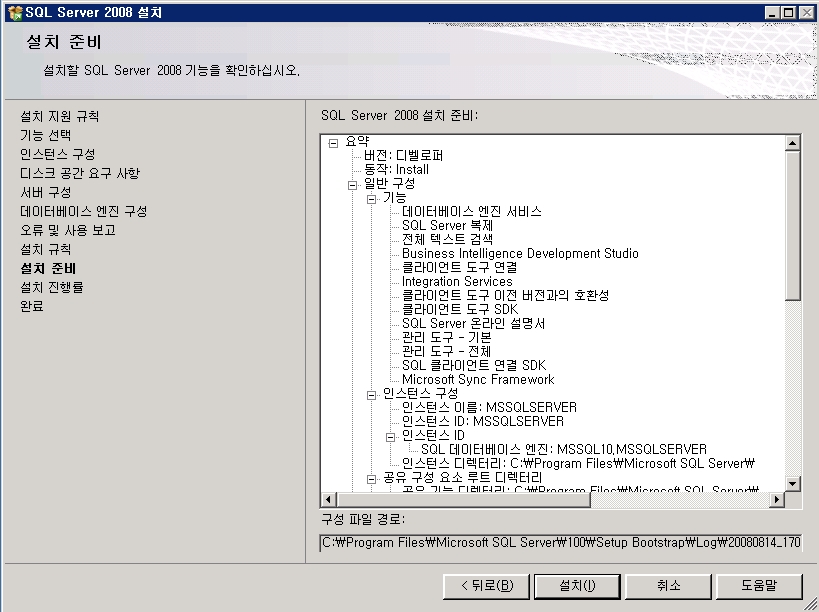
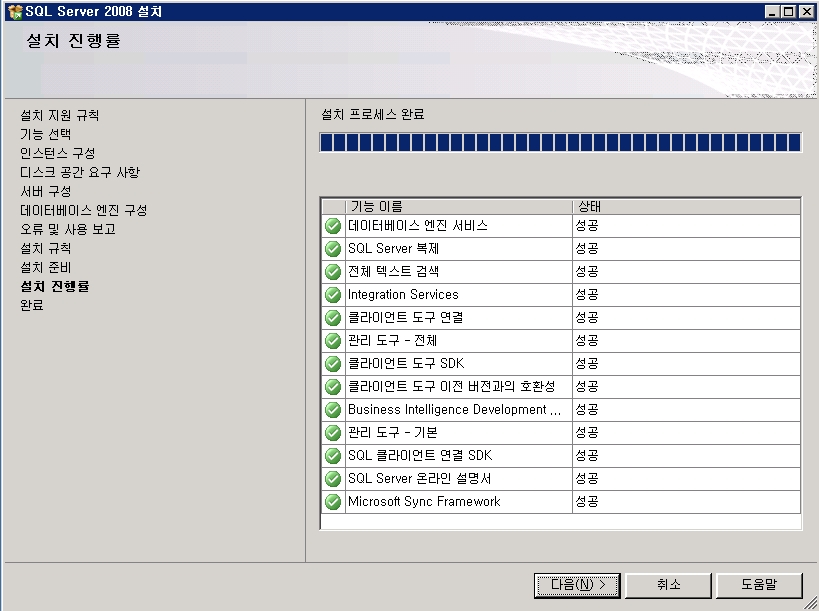
제목 : SQL Server 2008 - 새로운 DMV sys.dm_os_process_memory
SQL 프로세스의 메모리 상태에 대해서 보여주는 DMV입니다.
기존의 DBCC MEMORYSTATUS와 같은 SQL의 내부 메모리 개체에 대해서 보여주는게 아닌
OS입장에서의 프로세스 메모리에 대해서 보여줍니다.
x64환경이 보편화되어 이전보다 메모리에 대한 이슈가 있는 시점에
보다 쉽게 현재 문제 및 현재 상태에 대해서 파악 할 수 있을것 같습니다.
-- 아래는 온라인 설명서에서 발췌
SQL Server 프로세스 공간에 소요되는 대부분의 메모리 할당은 이러한 할당을 추적 및 계산하도록 허용된 인터페이스를 통해 제어됩니다.
그러나 메모리 할당은 내부 메모리 관리 루틴을 거치지 않는 SQL Server 주소 공간에서 수행될 수도 있습니다. 값은 기본 운영 체제 호출을 통해 얻습니다. 이러한 값은 잠긴 페이지 할당 또는 대용량 페이지 할당을 조절하는 경우를 제외하고는 SQL Server 내부 메서드에 의해 조작되지 않습니다.
메모리 크기를 나타내는 모든 반환 값은 킬로바이트(KB) 단위로 표시됩니다. total_virtual_address_space_reserved_kb 열은 virtual_memory_in_bytes from sys.dm_os_sys_info의 중복입니다.
다음 표에서는 프로세스 주소 공간의 전체적인 구조를 보여 줍니다.
|
열 이름 |
데이터 형식 |
설명 |
|
physical_memory_in_use |
bigint |
운영 체제에서 보고한 내용에 대용량 페이지 및 AWE API를 사용하여 수행된 추적된 할당을 더한 프로세스 작업 집합(KB)입니다. |
|
large_page_allocations_kb |
bigint |
대용량 페이지 API를 사용하여 할당된 물리적 메모리입니다. |
|
locked_page_allocations_kb |
bigint |
AWE API를 사용하여 할당된 물리적 메모리입니다. |
|
total_virtual_address_space_kb |
bigint |
가상 주소 공간에서 사용자 모드 부분의 총 크기입니다. |
|
virtual_address_space_reserved_kb |
bigint |
물리적 페이지에 커밋 또는 매핑되지 않은 가상 주소 예약의 크기입니다. |
|
virtual_address_space_committed_kb |
bigint |
물리적 페이지에 커밋 또는 매핑된 가상 주소 크기입니다. |
|
virtual_address_space_available_kb |
bigint |
현재 사용 가능한 가상 주소 공간의 크기입니다. |
|
page_fault_count |
bigint |
SQL Server 프로세스에서 발생한 페이지 폴트 수입니다. |
|
memory_utilization_percentage |
int |
작업 집합에 있는 커밋된 메모리의 비율입니다. |
|
available_commit_limit_kb |
bigint |
프로세스에서 커밋할 수 있는 메모리의 크기입니다. |
|
process_physical_memory_low |
bit |
프로세스가 물리적 메모리 부족 알림에 응답합니다. |
|
process_virtual_memory_low |
bit |
가상 메모리 공간이 부족한 것으로 감지되었습니다. |
송 혁, SQL Server MVP
sqler.pe.kr // sqlleader.com
hyoksong.tistory.com // nexondbteam.tistory.com
요즘 이리저리..정신 없는 날 들의 연속이라...
포스팅을 제대로 못하고 있네요...
이번에 적어본 내용은 SQL Server 2008의 새로운 기능에 대한 .. DW환경에서의 이점을 줄 수 있는..
쉽게 읽어볼 수 있는 주제인듯 합니다.
제목 : SQL Server 2008의 새로운 기능 - Star Join query optimization(multiple bitmap filters)
많은 DW 시스템은 Star 스키마로 구성 되어있으며, 이러한 스타 스키마로 구성된 대량의 팩트 테이블과 많은 차원 테이블에 대해서 데이터를 검색 하기 위해서는 많은 리소스 및 시간이 소요 됩니다.
이러한 많은 시간과 리소스에 대해서 어느 정도의 보완점이 될 수 있는 기능으로써 SQL Server 2008에서 새로운 기능으로 Star join query optimization을 지원하고 있습니다.
SQL Server 2008에서 Star Join이 추가된다고 해서 특별히 다른 물리연산자가 추가된 것은 아니며, 추가된 구문도 있지 않습니다.
여기서는 이 기능에 대해서 SQL Server 2005와 비교하여 실행계획이 어떻게 변경이 되었는지 확인해 보려고 합니다.
그리고!! 중요한 것은 Enterprise Edition에서만 지원합니다.
BOL에서는 Star join query optimization에 대해서 “비트맵 필터링을 통한 데이터 웨어하우스 쿼리 성능 최적화” 라는 제목으로 소개를 하고 있습니다.
비트맵은 SQL Server 2008 이전에도 존재했던 물리 연산자 이며 병렬 Hash, Merge 연산자에서만 사용될 수 있는 연산자 입니다.
그리고 SQL Server 2008에서 지원한다는 Star Join 쿼리 향상도 비트맵 연산자를 통해서 처리되고 있습니다.
그렇다면 기존에도 있는 연산자인데 왜!! 무엇을 지원한다는 것일까요?
SQL Server 2005 플랜과 2008플랜으로 무엇이 변경이 되었는지 아래에서 살펴보도록 하겠습니다.
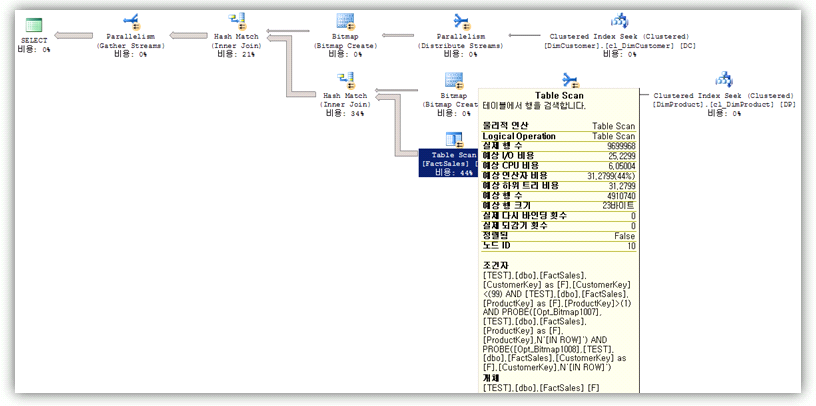
아래는 SQL Server 2005의 실행 계획이며, 하나의 팩트 테이블과 두 개의 차원테이블을 조인한 실행 계획입니다.
우선 DimCustomer 테이블을 읽어서 비트맵을 생성합니다.
그리고 DimProduct 테이블을 읽어서 비트맵을 생성하고 팩트 테이블을 읽어 병렬연산자(Repartition Streams)에서 위 DimProduct에서 생성된 비트맵을 바탕으로 필터조건을 주어 데이터 양을 줄이는 것을 볼 수 있습니다.
왜? 위에서 만든 DimCustomer의 비트맵도 같이 필터 조건을 주어 처리하면 처음부터 보다 적은 데이터 양으로 처리 할 수 있을 것인데, 왜 하나의 비트맵만..사용했을까요?
그럼 아래 SQL Server 2008의 실행계획을 보도록 하겠습니다.
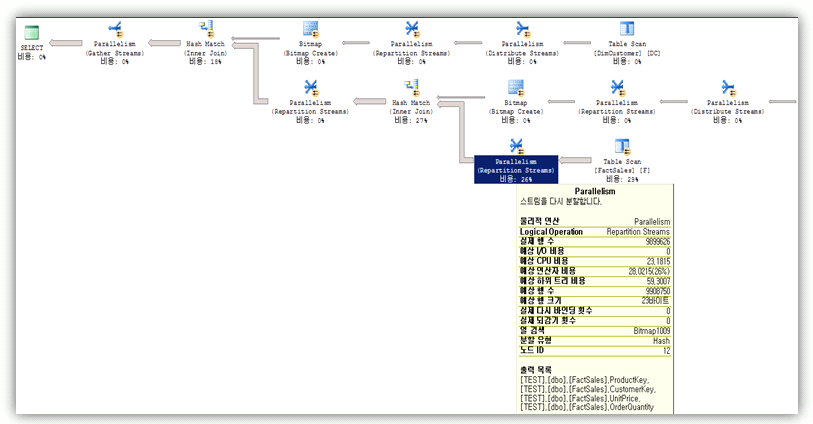
위 2005 플랜과 유사한 모습이며 여기서도 DimCustomer, DimProduct 테이블에 대해서 비트맵을 생성하는 것을 볼 수 있습니다.
하지만 팩트 테이블 스캔 연산자에서 “조건자” 부분을 보시면 위에서 생성된 비트맵 두 개를 가지고 테이블 스캔시에 필터를 하는 것을 확인 할 수 있습니다.
위 플랜과 차이점은 두 개 이상의 비트맵에 대해서 테이블 스캔시 Bitmap을 기반으로 필터를 하는 것입니다.
SQL Server 2005의 경우에는 하나의 비트맵으로 병렬연산자(Repartition Streams)에서 필터 조건을 주었습니다.
테이블 스캔시 필터를 하고, 여러 비트맵을 가지고 처리하기에 위 SQL Server 2005보다 좋은 성능을 가져올 수 있을 것 입니다.
PROBE([Opt_Bitmap1007],[TEST].[dbo].[FactSales].[ProductKey] as [F].[ProductKey],N'[IN ROW]') AND PROBE([Opt_Bitmap1008],[TEST].[dbo].[FactSales].[CustomerKey] as [F].[CustomerKey],N'[IN ROW]')
sqler.pe.kr
sqlleader.com
hyoksong.tistory.com
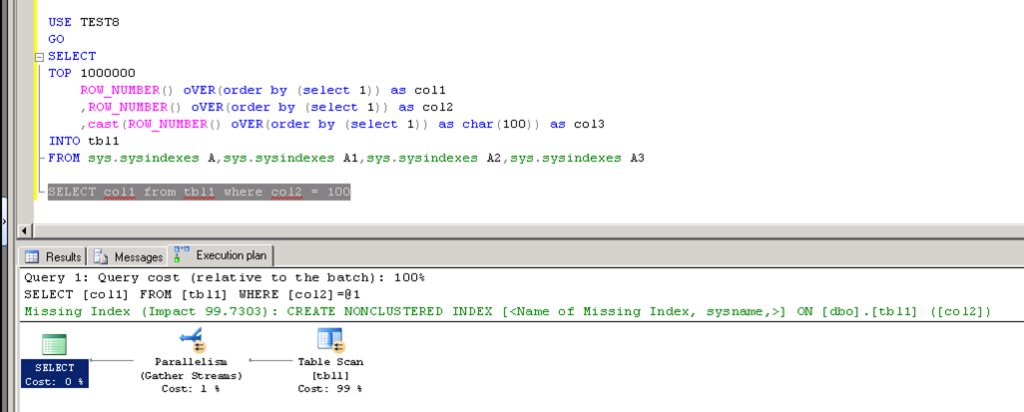
인덱스가 제대로 구성되지 않은 쿼리를 실행하면 아래와 같이 missing index라고 해서
현재 이 쿼리에 필요한 인덱스를 추천 해 주는 기능을 제공합니다.
sqler.pe.kr // sqlleader.com
hyoksong.tistory.com // nexondbteam.tistory.com
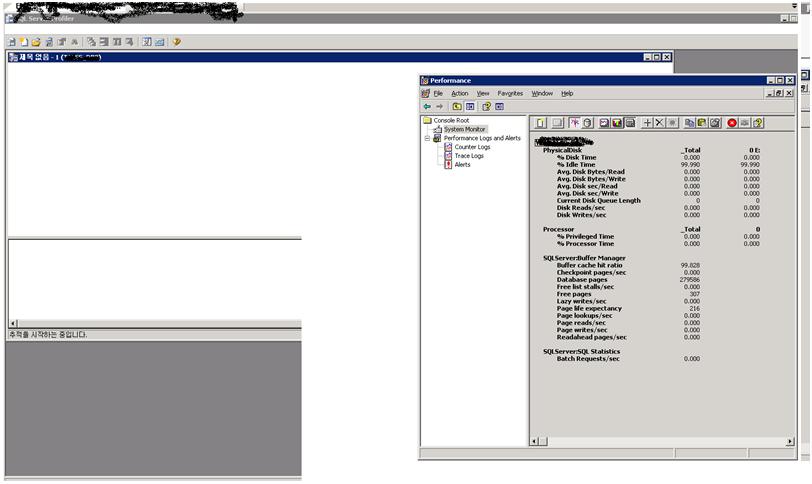
보통 busy한 서버에 대해서 프로필러와 같은 클라이언트 추적을 사용하지 않는 것이 권고 사항입니다.
클라이언트 추적으로 인해서 전체적인 서비스에 영향을 주며 특정경우에는 SQL 서비스가 중지가 되는 현상도 있었습니다.
이런 일반적인 내용에 대해서 정말 busy한 서버에 프로필러를 뛰우면 어떻게 되는지 테스트를 했습니다.
초당 16000정도의 요청을 받는 SQL서버에 프로필러를 사용해서 추적을 걸어본 결과
2번째 그림에서 볼수 있듯이 Batch Request/Sec이 0로 떨어지면서 프로필러도 응답이 없는 상태로 되었습니다.
만약 이게 실 서비스였다면 잠시나마 모든 요청에 대해 처리를 못해 큰 문제가 될 수 있습니다.
아래 사래와 같은 일이 실 서비스에서도 발생 할 수 있으니 클라이언트 추적을 사용시 보다 주의가 필요할 것으로 보입니다.
송 혁, SQL Server MVP
sqler.pe.kr // sqlleader.com
hyoksong.tistory.com // nexondbteam.tistory.com
<프로필러를 수행전> 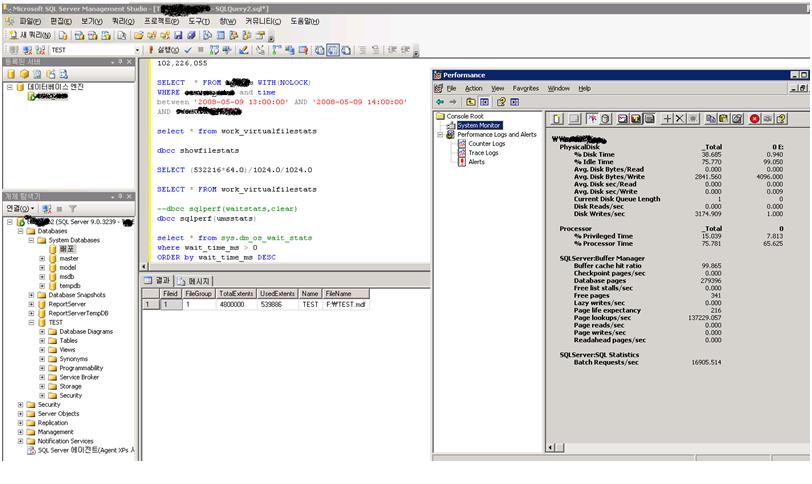
기존의 Trace를 대체할 수 있는 기능을 가졌으며
SQL Server의 내부 이벤트를 캡쳐하여 트러블슈팅 및 성능 문제 발생시
원인을 보다 쉽게 파악할수 있는 기능...
개인적으로는 SQL Server 2008의 기대되는 NEW feature중 하나~입니다.!!
DBCC DROPCLEANBUFFERS는 Buffer Pool에 존재하는 데이터 페이지를 제거하는 구문입니다.
하지만 DBCC DROPCLEANBUFFERS을 수행하면 정말 Buffer Pool에 있는 데이터 페이지가 사라질까요?
간단히 결론만을 말하면 아직 disk로 플러시 되지 않는 페이지는 이 구문으로 내려갈 수 없습니다.
모든 Buffer Pool에 있는 페이지를 내리려면 checkpoint를 통해서 Dirty페이지를 마크 후에 DBCC DROPCLEANBUFFERS를 수행 하면됩니다.
아래는 테스트 예제입니다.
USE TEST
GO
--DROP TABLE tbl1
--샘플 테이블 만들기
SELECT
TOP 1000
ROW_NUMBER() over(order by (select 1)) as col1
,cast('Hyoksong' as char(5000)) as col2
INTO tbl1
from sys.sysindexes A,sys.sysindexes B,sys.sysindexes C,sys.sysindexes B1
--Buffer Pool에있는 데이터 페이지를 날리자.
EXEC sp_msforeachdb 'USE ? CHECKPOINT 1'
DBCC DROPCLEANBUFFERS
--500개 행에 대해서 업데이트를 치자.
UPDATE tbl1
SET col2 = 'Test'
WHERE col1 > 500
(500개행적용됨)
--Buffer Pool의tbl1 테이블 데이터 페이지의 수는 몇개?
select
COUNT(*)
from sys.allocation_units a
right outer join sys.dm_os_buffer_descriptors b
ON a.allocation_unit_id = b.allocation_unit_id
left outer join sys.partitions p
ON a.container_id = p.hobt_id
WHERE B.database_id = db_id('Test')
and (p.object_id IS NULL OR p.object_id > 100)
and object_name(object_id,database_id) = 'tbl1'
and page_type = 'DATA_PAGE'
/*
결과: 1001
*/
--DBCC DROPCLEANBUFFERS 를수행하고Buffer Pool에는몇개?
DBCC DROPCLEANBUFFERS
select
COUNT(*)
from sys.allocation_units a
right outer join sys.dm_os_buffer_descriptors b
ON a.allocation_unit_id = b.allocation_unit_id
left outer join sys.partitions p
ON a.container_id = p.hobt_id
WHERE B.database_id = db_id('Test')
and (p.object_id IS NULL OR p.object_id > 100)
and object_name(object_id,database_id) = 'tbl1'
and page_type = 'DATA_PAGE'
/*
결과: 500
*/
--그럼Checkpoint를후에DBCC DROPCLEANBUFFERS을수행하면?
CHECKPOINT 1
DBCC DROPCLEANBUFFERS
select
COUNT(*)
from sys.allocation_units a
right outer join sys.dm_os_buffer_descriptors b
ON a.allocation_unit_id = b.allocation_unit_id
left outer join sys.partitions p
ON a.container_id = p.hobt_id
WHERE B.database_id = db_id('Test')
and (p.object_id IS NULL OR p.object_id > 100)
and object_name(object_id,database_id) = 'tbl1'
and page_type = 'DATA_PAGE'
/*
결과: 0
*/
송 혁, SQL Server MVP
sqler.pe.kr
sqlleader.com
hyoksong.tistory.com
nexondbteam.tistory.com
CHECKPOINT는 Buffer Pool의 커밋되지 않은 페이지를 디스크로 플러시를 하는 프로세스 입니다.
CHECKPOINT는 DB단위로 발생하며, 발생 주기는 recovery interval 옵션의 값을 기반으로 움직이게 됩니다.
CHECKPOINT 발생시 커밋되지 않은 페이지를 디스크로 페이지를 플러시 하며, CHECKPOINT가 발생한 시점에 트랜잭션 로그파일도 마킹을 하여
비정상적인 종료시 마지막 CHECKPOINT 이후의 트랜잭션 로그를 바탕으로 데이터를 롤백 또는 롤포워드 하게됩니다.
CHECKPOINT가 발생시 IO에 병목이 발생 할 수 있으며 이러한 문제의 해결에 도움을 줄 수 있는 몇가지 기능이 SQL Server 2005에 추가되었습니다.
1. CHECKPOINT Duration
è 수동 CHECKPOINT발생시 Duration 시간을 지정 할 수 있습니다.
BP에 있는 내용을 최대한 빨리 내릴경우에는 Duration을 1로 지정 할 수 있으며
자동 Checkpoint시 성능적 문제가 발생한 경우 수동 Checkpoint에 Duration값을 적절히 설정하면
천천히 페이지를 플러시 하여 IO에 급격한 요청을 피해 전반적인 성능 향상을 꾀할 수 있습니다.
2. -k 옵션 (http://support.microsoft.com/default.aspx/kb/929240)
è SP2에 누적 픽스 까지 설치하면 –k 시작 옵션을 사용할 수 있습니다.
해당 옵션은 초당 얼마의 IO작업을 할것인지 지정 할 수 있으며 만약 –k100으로 설정 하였다면
초당 100MB의 IO작업이 발생하게 됩니다.
위 Duration처럼 CHEKCPOINT시 병목에 대해서 해결시 사용할 수 있습니다.
보다 자세한 내용은 위 KB문서를 참고 하세요.
3. CHECKPOINT IO응답시간 20ms 이내, 서버 종료시는 100ms
è 2000의 경우에는 Checkpoint 작업시 DISK병목 현상이 발생될 수 있었지만
2005의 경우에는 Write 응답시간을 20ms 또는 100ms으로 지정하여 기존 버전보다 IO병목 현상에 대해 향상 되었습니다.
4. 연속된 32개의 페이지를 하나의 IO로 처리(기존 SQL Server 2000에는 16페이지)
è 보통 DISK는 랜덤IO 작업에 성능이 급격히 떨어지게 됩니다.
여러 개의 페이지를 하나의 IO작업으로 처리하면 보다 빨리 CHECKPOINT작업이 처리 될 수 있습니다.
2000의 경우에는 16개의 페이지 였지만 2005의 경우에는 32개의 페이지를 하나의 IO로 처리 할 수 있습니다.
CHECKPOINT는 IO성능에 가장 이슈가 되는 프로세스이며, 조금 더 살펴보면 재미 있는 이슈가 많습니다.
조만간 아래 주제에 대한 글을 포스팅 하도록 하겠습니다.
1. 연속적, 랜덤한 데이터 변경에 대한 CHECKPOINT 성능 비교
2. CHECKPOINT를 발생시키는 이벤트
3. IO Subsystem의 성능에 따른 CHECKPOINT
4. 매뉴얼 CHECKPOINT,-k 시작 옵션, Duration은 언제 사용할까?
5. DBCC DROPCLEANBUFFERS 를 수행하면 모든 페이지가 정말 Buffer Pool에서 사라질까?
송 혁, SQL Server MVP
sqler.pe.kr
sqlleader.com
hyoksong.tistory.com
nexondbteam.tistory.com